第8章: Goal Workflow —— 目标驱动的研发闭环
"你只需描述功能想法,剩下的交给工作流。"
——smallnest, Goal Workflow 作者, 2026 年 5月
三条路。gstack 覆盖从需求到交付,但你得手动驱动每个阶段。superpowers 覆盖从设计到代码,但止步于开发分支。autoresearch 覆盖从 Issue 到合入,但它假设 Issue 已经存在。每条路都只解了一段。
实际项目不是这样的。实际项目从一句"我想做一个东西"开始。然后你要搞清楚它是什么、设计它怎么做、拆成小块、逐块实现、审查代码、记录决策、最后合入上线。七个动作,缺一个就是断点。每个断点都是你手动接续的地方。
Goal Workflow 做的事就是把这些断点接上。不是做一个更强的 /goal 命令。是做一条流水线——七个斜杠命令,首尾相连,从 PRD 到上线。
8.1 smallnest 的两次转向
smallnest 是 Go 生态里的熟面孔,rpcx 微服务框架的作者,也是本书的作者, 百度公司的网络软件架构师。2026 年上半年,他连续发布了两个 AI 研发工具——先做了 autoresearch(第 7 章),然后又做了 Goal Workflow。
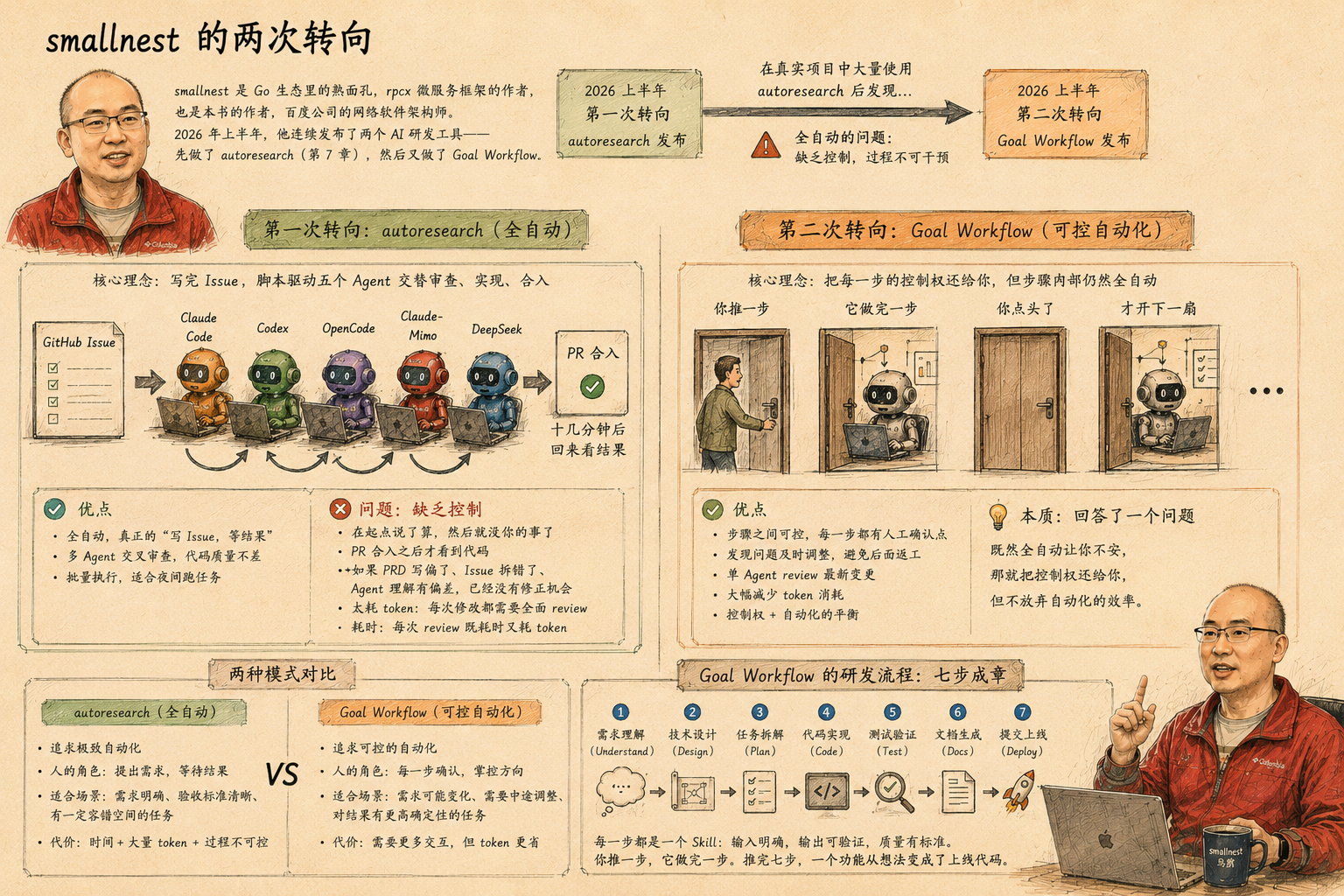
这个顺序本身就有意思。autoresearch 追求的是全自动——你写完 Issue,脚本驱动五个 Agent 交替审查、实现、合入,十几分钟后回来看结果。他在真实项目里大量使用 autoresearch 之后,发现了全自动的问题。
不是质量问题。autoresearch 产出的代码质量不差——两到五个 Agent 交叉审查,正确性、安全性、性能都覆盖了。问题是控制。全自动意味着你在起点说了算,然后就没你的事了。PR 合入之后你才看到代码,如果 PRD 写偏了,Issue 拆错了,或者 Agent 对验收标准的理解和你不一样——你已经没有修正的机会了。
Goal Workflow 是他对这个问题的回答。既然全自动让你不安,那就把每一步的控制权还给你。但控制不等于手动——每个步骤内部仍然全自动,步骤之间留一个门,你点头了才开下一扇。
最重要的一点,autoresearch太耗token了,每一次修改都需要进行全面的review,每次review既耗时又耗token,我们不太可能像Claude Code的作者一样无限制的使用最好的LLM,我们必须考虑到成本。Goal Workflow这种单agent review 最新的变更的方式可以有效的减少token的消耗。
和前面几章不同,Goal Workflow 不跟你讲 Agent 自主性或多 Agent 轮转。它做的事更朴素:把研发流程中每一步写成一个 Skill,每个 Skill 有明确的输入、输出和质量标准。你推一步,它做完一步。推完七步,一个功能从想法变成了上线代码。
8.2 安装与配置:一条 npx 命令装完全套
Goal Workflow 由 smallnest 维护,代码仓库 github.com/smallnest/goal-workflow,官网 goal.rpcx.io。核心是一组 Markdown Skill 文件,通过 npx skills 分发——这是第 2 章 Skills 哲学的直接实践:用包管理工具安装 Skill,像 npm 装依赖一样。
8.2.1 前提条件
三条:GitHub CLI(gh)、Claude Code CLI(claude)、Node.js(提供 npx)。
brew install gh && gh auth login
npm install -g @anthropic-ai/claude-codegh 是 /ship-it 和 /to-issues(GitHub 模式)的前置,没有它 PR 创建和 Issue 操作走不了。Claude Code 是 Skill 的运行宿主。npx 随 Node.js 安装,是 npx skills 的前提。
8.2.2 安装
安装全部 Skill(七个核心 + 七个增强,共十四个):
npx skills add smallnest/goal-workflownpx skills 做四件事:拉取仓库中的 Skill Markdown 文件、注册到 Claude Code 的 skills 目录、生成对应的 / 斜杠命令、写入 CLAUDE.md 配置。
也可以只装单个 Skill:
npx skills add smallnest/goal-workflow --skill prd--skill 后面跟 Skill 名——prd、prd-to-spec、to-issues、review-it、ship-it、note-it、humanize-it、listenhub-tts、insight-diagram、refactor、modern-go、code-to-spec、smell。挑需要的装。
全局安装(所有项目共用):
npx skills add smallnest/goal-workflow -g指定 Agent(非 Claude Code,如 Codex):
npx skills add smallnest/goal-workflow -a codexGoal Workflow 的 Skill 可以在 Claude Code、Codex、OpenCode、DeepSeek TUI 四种 Agent 上运行。唯一例外是 /goal——它是 Claude Code 的内置命令,Skill 包里不包含它。Codex 上的等价命令是 codex --goal "..."。
8.2.3 目录结构
安装后,项目目录下自动生成以下结构:
tasks/
├── prd-[feature-name].md ← /prd 生成的 PRD 文档
└── spec-[feature-name].md ← /prd-to-spec 生成的 SPEC(可选)
.autoresearch/
└── issues/ ← /to-issues 生成的本地 Issue 文件
docs/
├── issue#XXXX.html ← /note-it 生成的实现笔记
├── SPEC.md ← /code-to-spec 生成的反向规格
└── *.html ← /insight-diagram 生成的 UML 图tasks/ 放 PRD 和 SPEC,.autoresearch/issues/ 放本地 Issue(和第 7 章的 autoresearch 共用同一套本地 Issue 系统),docs/ 放设计文档、笔记和图。
8.2.4 平台支持
| Agent | 支持 | 备注 |
|---|---|---|
| Claude Code | 全部 Skill | /goal 内置,其余通过 Skill 包 |
| Codex | 全部 Skill | /goal 内置,其余通过 Skill 包 |
| OpenCode | 除 /goal 外全部 |
/goal 不适用 |
| DeepSeek TUI | 全部 Skill | /goal (/mubiao)内置,其余通过 Skill 包 |
Issue 创建支持三种平台:GitHub(gh issue create)、本地(.md 文件写入 .autoresearch/issues/)、百度 iCafe(icafe-cli)。
8.2.5 升级
重跑安装命令即可——覆盖 Skill 文件,CLAUDE.md 中的已注册命令自动更新:
npx skills add smallnest/goal-workflow版本管理和 Skill 包注册由 npx skills 生态维护,Goal Workflow 本身不内置升级逻辑——这和 gstack 的 /gstack-upgrade 不同,更接近 OpenSpec 的 openspec update。
8.3 流水线思维
Goal Workflow 的设计哲学和前面几章都不一样。gstack 相信角色覆盖——二十三个角色审查二十三个维度。superpowers 相信工具覆盖——十四个 Skill 覆盖十四个场景。autoresearch 相信模型覆盖——五个 Agent 交叉审查,不同模型的盲区互补。
Goal Workflow 相信的是流水线。每个工序有明确的输入、输出和质量标准。工序之间首尾相接,上游的输出是下游的输入。流水线不保证每个工序都完美。它保证的是工序之间没有裂缝。
这种思维在第 1 章就有了——"在 AI 时代,你的价值不再是'你能写多快的代码',而是'你能不能定义清楚什么算做好'。"Goal Workflow 把这句话拆成了七步。PRD 定义需求的标准,SPEC 定义技术的标准,Issue 定义验收的标准,/goal 把标准变成代码,/review-it 验证代码是否达标,/note-it 记录为什么这样达标,/ship-it 把达标的代码送上生产线。每一步都问:这一阶段的"做好"是什么?然后让 Agent 去做到。
流水线在制造业用了一百年。把它搬到 AI 软件工程上,Goal Workflow 是第一套完整方案。前面的方法论都在解决"如何让 Agent 做得更好"——更好的 prompt、更好的审查、更好的模型组合。Goal Workflow 在解决另一个问题:如何让人更好地组织 Agent 的工作。与其绞尽脑汁让一个 Agent 一次性做对所有事,不如把流程切成七段,每段只要求 Agent 做好一件事。
8.4 /goal:流水线的引擎
Goal Workflow 的流水线里,/goal 是唯一不在 skills 目录下的命令。它不是 smallnest 写的 Skill,是 AI 编码工具的内置功能。Goal Workflow 把它放在流水线正中心,让它成为"把 Issue 变成代码"的那一步。
/goal 的概念最早来自 Codex CLI。2025 年 4 月,OpenAI 发布了 Codex CLI,首次引入了 /goal 斜杠命令。核心思想是"声明式编程"——你说目标,Agent 自己拆步骤。在这之前,AI 编码工具的交互都是"指令式"的:你说一步,Agent 做一步。Codex 把这个范式颠倒了过来。
Codex 之后,Claude Code 也内置了 /goal。到了 2026 年 5 月,Google 的 Antigravity CLI 正式发布,同样带着 /goal 登场。
三个工具,独立设计,三种底层模型(GPT-5、Claude 4.x、Gemini 2.5),却选择了同一个词。这不是巧合。它们都在解决同一个问题:如何让人类从"指挥每一步"变成"定义目标,然后放手"。
当然,实现各有侧重。Codex 提供了完整的生命周期管理——目标可以暂停、恢复、编辑、清除。Agent 自主但不失控,用户随时介入。Claude Code 的 /goal 更务实——接收 Issue 编号或文件路径,读取验收标准,端到端实现,逐条验证 checkbox。Antigravity CLI 最晚入场,吸收了前两者的经验,加上 Gemini 的长上下文优势,处理多文件项目时更从容。
| 维度 | Codex /goal |
Claude Code /goal |
Antigravity CLI /goal |
|---|---|---|---|
| 发布时间 | 2025 年 4 月(首个) | 2026 年 5 月 | 2026 年 5 月 |
| 底层模型 | GPT-5 / Codex 系列 | Claude 4.x | Gemini 2.5 |
| 目标管理 | 完整生命周期(暂停/恢复/编辑/清除) | 设置目标,逐条验证 | 完整生命周期 + Issue 联动 |
| 验收方式 | 目标完成判断 | 逐条对照 Issue checkbox | 目标完成 + Issue checkbox |
| 安全模型 | 默认确认执行 bash 命令 | 权限模式(ask/auto) | 沙箱隔离 |
| 上下文优势 | 代码推理 | 深度推理、复杂重构 | 长上下文、多文件项目 |
| 最佳场景 | 放手式自主开发 | 需要随时干预的开发 | 大型多文件项目 |
和 Ralph Loop(第 4 章)比,/goal 是它的单次迭代实例化。核心循环一样——读需求、写代码、验证。区别在判断"做完"的方式。Ralph Loop 靠 completion promise 匹配——Agent 声明"做完了",匹配到就停。/goal 靠 Issue 的 checkbox 验收标准——Agent 不自己判断,逐条对照。
Goal Workflow 的流水线在三个平台上都能跑。除了 /goal 这一步的调用方式不同,其余六个 Skill 完全通用。Goal Workflow 做的事是让 /prd 和 /to-issues 生成的 Issue 格式正好匹配 /goal 期望的输入——PRD → Issue → /goal,三者的接口是对齐的。
8.5 七个步骤
Goal Workflow 的核心流水线:
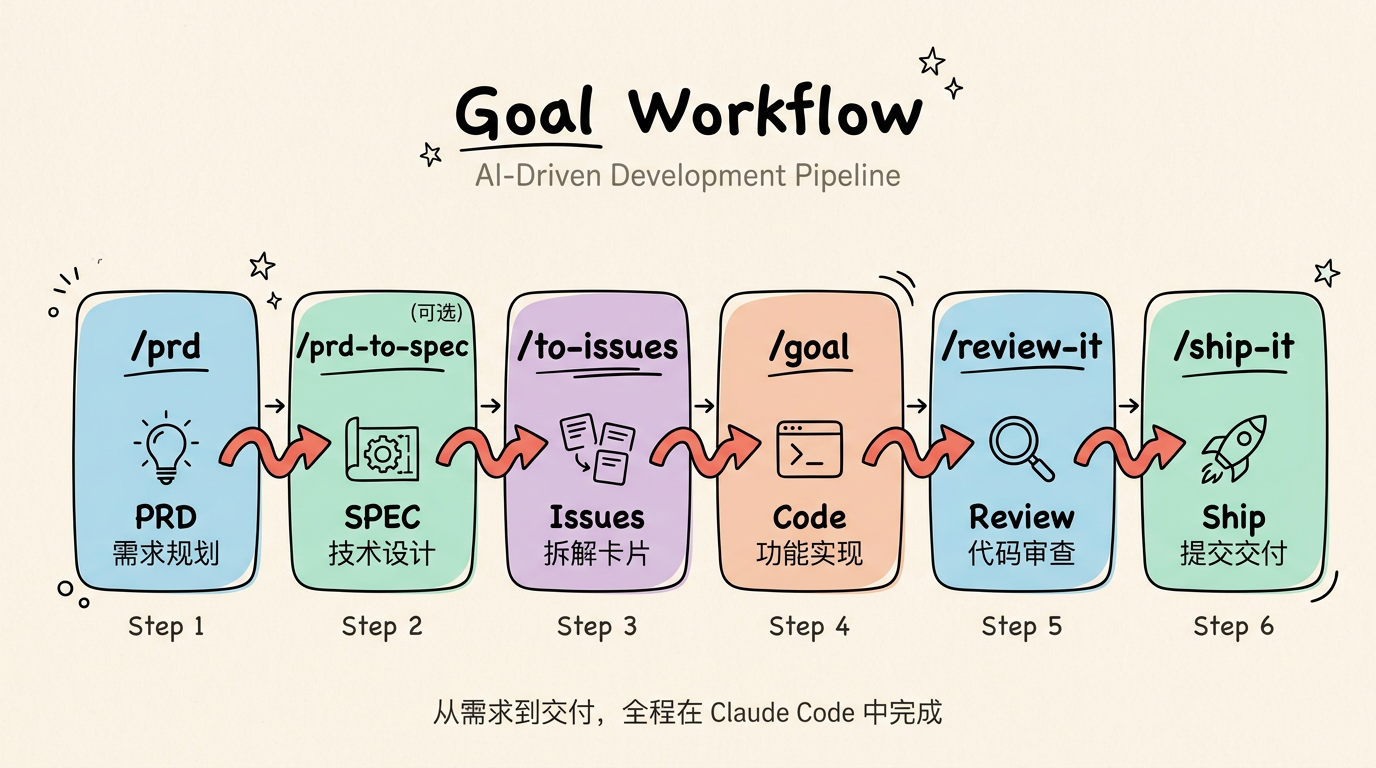
/prd → /prd-to-spec (可选) → /to-issues → /goal → /review-it → /note-it (可选) → /ship-it| 步骤 | 命令 | 输入 | 输出 | 角色隐喻 |
|---|---|---|---|---|
| 1. 规划 | /prd |
功能描述 | PRD 文档 | 产品经理 |
| 1.5 设计 | /prd-to-spec |
PRD 文档 | 技术 SPEC | 架构师 |
| 1.6 拆解 | /to-issues |
PRD / SPEC | Issue 卡片 | Tech Lead |
| 2. 实现 | /goal |
Issue 卡片 | 可运行的代码 | 开发工程师 |
| 3. 审查 | /review-it |
代码变更 | 通过审查的代码 | 代码审查者 |
| 3.5 记录 | /note-it |
已审查的代码 | 实现笔记 (HTML) | 开发工程师 |
| 4. 交付 | /ship-it |
已审查的代码 | 已合入的 PR + 已关闭的 Issue | 发布工程师 |
七个步骤,四个角色隐喻。gstack 有二十三个角色,Goal Workflow 少得多。区别不在数量。gstack 的角色是人格化的——"你是一个有十五年经验的员工工程师"。Goal Workflow 的角色是功能化的——每个角色就是一个命令要做的事。你不扮演产品经理,你调用 /prd 让 Agent 生成 PRD。角色隐喻帮你理解命令在流程中的位置,不是让你去扮演。
两步标了"可选":/prd-to-spec 和 /note-it。小功能 PRD 的验收标准就够了,不需要完整技术方案。简单实现不需要单独记录设计决策。但复杂功能少了这两步,Issue 拆解和后续维护都会受影响。
除了核心流水线,还有四个 Bonus Skills——/refactor、/modern-go、/code-to-spec、/insight-diagram——不参与流水线,各自独立使用。
下面走一遍实战。用 Goal Workflow 开发网页版贪吃蛇——同一个案例,第七种体验。每一步我会讲清楚发生了什么,以及背后的设计逻辑。
8.6 第一步:一句话生成 PRD
打开 Claude Code,输入:
/prd 做一个贪吃蛇网页游戏。纯前端单文件 HTML/CSS/JS 实现。演示 AI 编码能力。Agent 没有直接开始写文档。它先问了五个问题,每个带选项:游戏复杂度(简化/完整/极简)、功能范围(蛇移动/吃食物/碰撞死亡/最高分持久化)、技术偏好(纯单文件无框架/轻量框架/React)、UI 要求(简洁/像素风/现代)、代码质量侧重(结构清晰/性能优先/可维护性)。
这是 /prd 和 superpowers 的 brainstorming 的关键区别。superpowers 一次一个问题,逐个推进——适合需要深度讨论的探索性任务。/prd 一次甩出五个带选项的问题,你快速回复"1B, 2ABCD, 3A, 4A, 5A",适合目标明确、只需确认细节的功能开发。
澄清完成后,Agent 生成一份 PRD,包含问题陈述、可衡量目标、User Story(每个带 checkbox 验收标准)、功能需求(编号,用"系统必须/应当")、非目标(明确不做什么)、成功度量、待确认问题。保存到 tasks/prd-snake-game.md。
SDD(第 3 章)说"先写规格,再写代码"。/prd 是这句话的工程化落地——你不需要掌握方法论框架,描述想法就行,Agent 产出规格文档。SDD 是施工规范,/prd 是规范指导下的预制构件。
贪吃蛇这个例子够简单——单文件实现,没有后端,没有 API——所以跳过 /prd-to-spec。但值得说一下什么时候该走这一步。
/prd-to-spec 做的事是把"做什么"翻译成"怎么做"。PRD 说功能,SPEC 说架构、数据模型、API 设计、错误处理、安全、性能。它的产出里有两样东西最实用:Issue 映射表(把 SPEC 每个章节映射到对应 Issue,标注优先级和依赖)和验收标准映射表(每条 PRD 验收标准对应至少一个测试用例)。规格里有、代码里就有——不是靠人记忆,是靠文档的强制关联。
复杂功能值得走这一步。原因和 gstack 的 Think 阶段一样:在设计阶段找出问题,比在代码里找出问题代价低十倍。小功能跳过就行。
SPEC 有一个尴尬:写得越详细,和代码的同步成本越高。功能迭代后代码变了,谁来更新 SPEC?Goal Workflow 的答案是 /code-to-spec(后面会讲)——从代码逆向生成 SPEC。正向一次,逆向一次,保持同步。
8.7 为什么可以跳过 prd-to-spec
流水线图上 /prd-to-spec 标了"可选",这不是客气。是设计。
/prd 产出的 PRD 本身就是一份规格文档——产品级的规格。它包含 User Story(每个带 checkbox 验收标准)、功能需求(编号,用"系统必须/应当")、非目标、技术考量。这些内容已经足够让 /to-issues 和 /goal 工作了。/to-issues 的 SKILL 文件里写着:如果只有 PRD 没有 SPEC,直接从 User Story 生成 Issue。
不是文档不够详细所以妥协。是故意的模块化设计。
PRD 的 User Story 格式是被刻意约束过的——每个 Story 的验收标准必须是可验证的 checkbox 列表。"按钮点击后弹窗出现"是可验证的。"用户体验良好"不行。有了这个约束,PRD 的验收标准本身就能当测试用例用,不需要 SPEC 再翻译一遍。
贪吃蛇刚好说明这一点。四个 User Story,"20x20 网格渲染正确""蛇初始长度 3""撞墙触发 game over",全是可验证的 checkbox。/goal 拿到就能直接实现。中间插一个 SPEC 去描述"Canvas 渲染采用 requestAnimationFrame 驱动主循环",对 Agent 帮助不大,对读者负担不小。
那什么时候该走 /prd-to-spec?当 PRD 的 User Story 描述不了"怎么做"的时候。
一个典型场景:功能涉及多个服务或模块。PRD 说"用户登录后看到个性化推荐",但推荐服务怎么调、缓存怎么设计、降级策略是什么——这些 PRD 管不着,得 SPEC 来约定。
另一个:有 API 设计或数据模型变更。新增接口、改数据库 schema、破坏性变更。SPEC 的 Issue 映射表在这里价值最大——把 API 端点、数据迁移、业务逻辑拆进不同的 Issue,标注依赖。
再加一个:多人并行。前后端分离,多个 Agent 同时实现不同 Issue。SPEC 是它们之间的共享合约。
功能越简单,PRD 和 SPEC 的重叠越大。贪吃蛇这个级别,PRD 已经把能说的都说了——单文件 HTML,没有后端,没有 API,没有数据库。SPEC 能补充的东西几乎为零。
反过来,功能越复杂,PRD 和 SPEC 的分工越清晰。PRD 回答"用户看到什么、能做什么"。SPEC 回答"系统怎么做到"。两者不重复,各管各的。
这也解释了 Goal Workflow 和 SDD(第 3 章)的区别。SDD 说"必须先有规格再写代码",对所有功能一样。Goal Workflow 说:规格有好几层。产品规格(PRD)对所有功能都是必须的。技术规格(SPEC)只在复杂度超过阈值时才需要。阈值在哪?你读完 PRD,不确定 /goal 能不能独立完成的时候。
PRD、设计文档、SPEC
这三个词在中国研发体系里经常混着用。理清它们的区别,才能理解为什么 Goal Workflow 选了 SPEC 而不是"设计文档"。
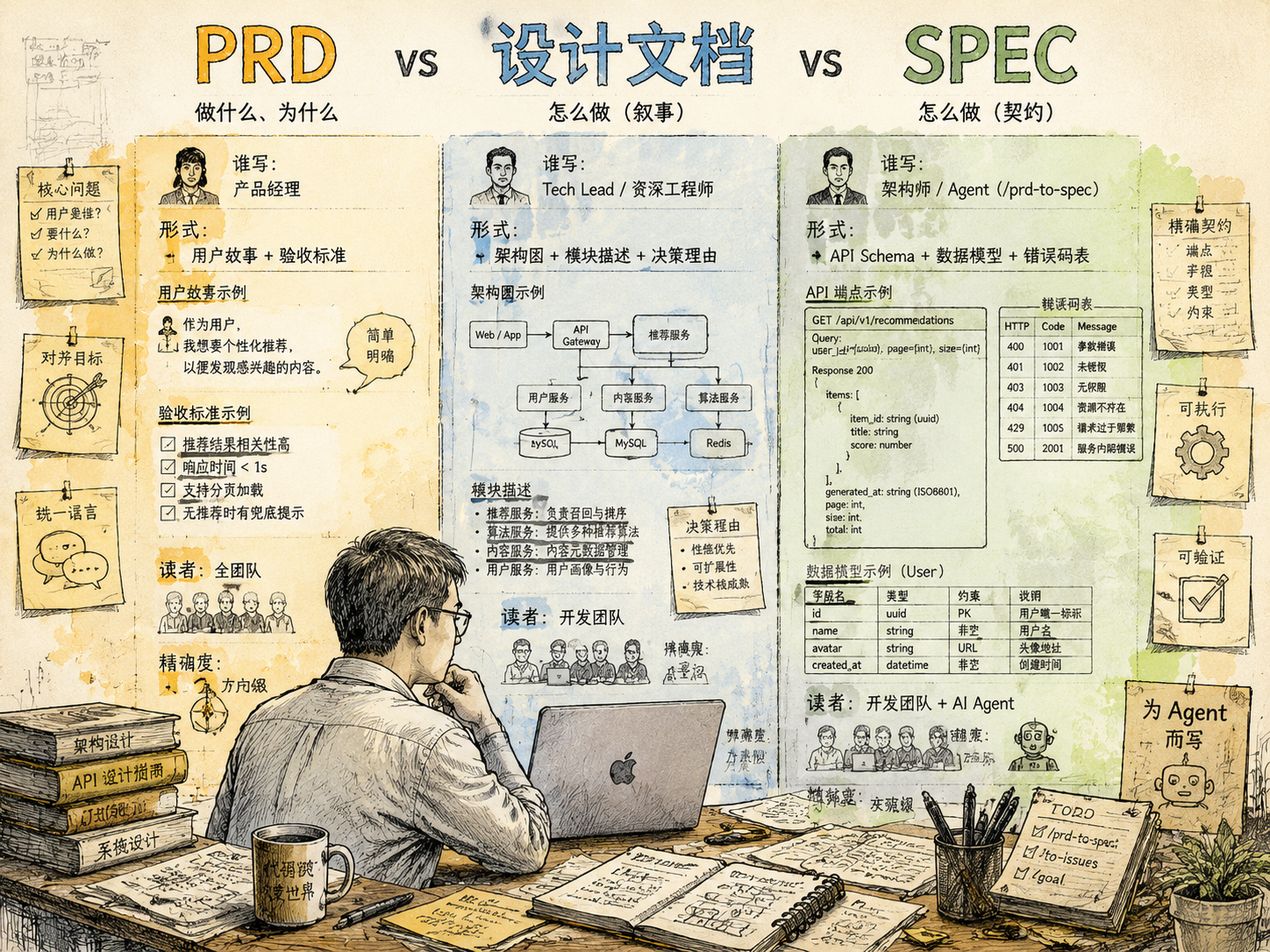
| PRD | 设计文档 | SPEC | |
|---|---|---|---|
| 谁写 | 产品经理 | Tech Lead / 资深工程师 | 架构师 / Agent(/prd-to-spec) |
| 回答什么 | 做什么、为什么 | 怎么做(叙事) | 怎么做(契约) |
| 形式 | 用户故事 + 验收标准 | 架构图 + 模块描述 + 决策理由 | API Schema + 数据模型 + 错误码表 |
| 读者 | 全团队 | 开发团队 | 开发团队 + AI Agent |
| 精确度 | 方向级 | 方案级 | 实现级 |
PRD 最简单。产品经理写,用户是谁、要什么、验收标准是什么。所有人对"做成什么样"的理解对齐。
设计文档是中国研发体系里最常见的中间产物。Tech Lead 在动手前写一份,讲架构怎么设计、模块怎么拆、为什么选这个方案。叙事型的——读起来像一篇文章,"我们打算这么干,理由是这些"。对人友好,对机器不够友好。Agent 拿到一份设计文档,能理解意图,但没法直接执行。"API 返回用户画像数据"不如"GET /api/v1/recommendations?user_id={uuid} → 200 { items: [], generated_at: ISO8601 }"好执行。
SPEC 不一样。它不是解释,是约定。契约型的——API 端点精确到路径和响应 Schema,数据模型精确到字段类型和约束,错误处理精确到错误码和 HTTP 状态码。人读起来啰嗦,Agent 读起来刚好。
Goal Workflow 的 /prd-to-spec 产出的就是这种契约型 SPEC——十一个章节,从架构到 API Schema 到错误分类到 Issue 映射表。不是让你读的(虽然你可以读),是让 /to-issues 拆解和 /goal 实现用的。PRD 给方向,SPEC 给精确坐标。
设计文档和 SPEC,本质都是把"怎么做"写下来。区别是读者。只有一个你和一个 Agent 在看,PRD 的验收标准就是够好的"怎么做"。当三个 Agent 加一个前端团队一起看,你才需要 SPEC 那份精确度。
8.8 第二步:拆成 Issue
/to-issuesAgent 自动定位刚才生成的 PRD,把四个 User Story 拆成四个 Issue:
#1: HTML 结构与 Canvas 渲染 (frontend, high)
#2: 游戏循环与方向控制 (frontend, high) — depends on #1
#3: 碰撞检测与食物系统 (frontend, high) — depends on #2
#4: 分数系统与 UI 状态 (frontend, high) — depends on #1, #2, #3拆解规则是隐式的,但可以反推出来:一个 User Story 至少一个 Issue;验收条件超过五条的 Story 拆成两到三个;太简单的合并;每个 Issue 必须能在一个 Agent 会话中独立完成。
这些规则是从 autoresearch 的经验中提炼出来的。Issue 太大,Agent 在上下文窗口里迷路。Issue 太小,启动成本高于实现成本。/to-issues 的粒度瞄准的就是这个区间。
Agent 展示 Issue 列表让你审核。你可以删除、合并、新增、调整优先级。确认后选择创建平台——GitHub(gh CLI)、本地文件、百度 iCafe——Agent 逐个调用对应 CLI,不需要手动复制粘贴。
这里有一个刻意的设计:/to-issues 创建的本地 Issue 文件,格式直接兼容 autoresearch 的 --issues-dir 参数。Goal Workflow 和 autoresearch 同作者,这种一致性不是偶然。拆解完想全自动?丢进 autoresearch。想手动逐个来?用 /goal。
8.9 第三步:逐个实现
/goal .autoresearch/issues/issue-001-snake-game-render.mdAgent 读取 Issue #1,理解验收标准——20x20 网格、初始长度 3 的蛇、Canvas 绘制。端到端实现,产出 snake-game/index.html 的基础结构和 Canvas 渲染层。
然后逐个推进:Issue #2 实现游戏循环和方向控制(requestAnimationFrame + 手动计时,方向缓冲防反向),Issue #3 实现碰撞检测和食物系统(随机生成、检查不重叠蛇身),Issue #4 实现分数系统和 UI(当前分/最高分、HTML modal 弹窗、localStorage 持久化带 try-catch、空格键重置)。
这里能看出 /goal 的设计哲学:"单次会话完成一个功能"。上下文窗口里的所有内容都和当前 Issue 相关。不会出现 Ralph Loop 中上下文膨胀的问题——Issue 太大早被 /to-issues 拆掉了。不会出现 autoresearch 多 Issue 间依赖混乱的问题——依赖在拆解阶段就已标注,你按顺序逐个 /goal 就行。
和 autoresearch 比,/goal 是手动版。每次实现一个 Issue,你在旁边看着。autoresearch 一口气吞下所有 Issue,你喝茶睡觉。核心实现逻辑一样——读 Issue、写代码、跑测试。区别在循环由谁驱动。你驱动,是 Goal Workflow。脚本驱动,是 autoresearch。
8.10 第四步:审查
/review-itAgent 检测四个 /goal 产出的代码变更,发起审查。四个维度:代码质量(命名、结构)、功能完整性(对照每个 Issue 的验收标准逐条核实)、安全性(localStorage 的 try-catch 是否在位)、性能(requestAnimationFrame 实现是否正确)。
审查发现两个问题。第一个是 modal 弹窗出现后方向键仍能控制蛇——和第 5、6 章实战中抓到的同一个问题。第二个是空格键重置后蛇状态未完全初始化。Agent 修复,重新审查,通过。
/review-it 的审查逻辑和第 7 章 autoresearch 的质量门禁类似,但控制权在你手里。流程是:检测变更 → 发现问题 → Agent 修复 → 重新审查 → 直到无 actionable findings。支持四个 Agent——Claude Code、Codex、OpenCode、DeepSeek TUI。
审查结论是建议,不是命令。"Treat review output as advisory. Never blindly apply it."Agent 对每条发现都要验证:读代码、读依赖、拒绝不合理的边界情况、拒绝过度工程化的修改。这和 gstack 的"角色审查 → 你有否决权"逻辑一致。自动化不是 AI 说了算,是 AI 找了问题,你判断该不该修。
审查通过的标准不是"没有发现问题",是"没有需要修复的问题"。审查者可能提出建议但你决定不修——只要解释清楚为什么不修,就是通过。
8.11 第五步:记录设计决策
/note-itAgent 回顾四个 Issue 的实现过程,记录四条设计决策:为什么用 requestAnimationFrame 而非 setInterval(帧同步精度)、为什么方向缓冲不在键盘事件中直接更新(防止一帧内多次转向)、为什么 localStorage 用 try-catch 包裹(隐私模式兼容)、为什么 modal 弹窗出现时拦截所有键盘事件(防止死蛇漂移)。
输出是一份 HTML,存在 docs/issue#0001.html。设计得很轻——四条彩色标签,每条对应一个类别:设计决策、偏离、权衡、待确认。空类别直接写"None"。
代码能告诉你"怎么做",但很难告诉你"为什么这样做"。/note-it 填补这个空白。smallnest 把它放在 /review-it 之后、/ship-it 之前,位置是有意的:审查通过意味着代码质量合格,此时回头记录设计决策,既不受审查来回修改的干扰,也不会被交付后的遗忘抹掉。
还有一个容易被忽略的价值:这些记录对 AI Agent 的后续维护极其有用。Agent 下次修改相关代码时,读到 docs/issue#0042.html 就能理解当初的设计考量。注释在代码里,只能解释当前实现。设计笔记记录的是"当初还有别的选择,为什么没选"。Agent 知道什么路试过但死了,就不会再试一次。
8.12 第六步:交付
/ship-itAgent 执行六步机械操作:创建分支 → 暂存相关文件(不混入无关变更)→ commit message 关联 Issue 编号 → 推送 → 创建 PR → squash merge → 删除分支 → 在 Issue 上添加实现总结评论。
和第 7 章 autoresearch 的收尾逻辑一样:传统 CI 到"代码能跑"就停了,PR 创建、等待 CI、合并、关闭 Issue 都要人手动做。每一步都是延迟和出错的机会。/ship-it 把它们全部自动化。
但有一个区别:/ship-it 需要你明确调用。autoresearch 在第 4 轮评分达标后自动合入——你不说合,它也合了。Goal Workflow 把控制权留给你——走完 /review-it,确认没问题,再敲 /ship-it。多一步手动,少一次意外合入。
PR 合入后,Agent 在 Issue 上评论一条总结——核心变更、PR 编号、commit hash。Issue 变成了可回溯的功能档案:Issue → PR → Commit → Code → Note,完整的一条链。
8.13 实战:用 Goal Workflow 开发网页版贪吃蛇
本书每一章都用贪吃蛇作为实战案例。这是第七种体验——不是跑一条命令,不是写一个 Issue,而是走完一条完整流水线。
8.13.1 第一步:/prd 生成需求文档
在 Claude Code 中输入:
/prd 做一个贪吃蛇网页游戏。方向键控制蛇移动,吃食物变长得分,
撞墙或撞自己结束。纯前端单文件,最高分 localStorage 持久化。Agent 追问三个澄清问题:
Q1: 游戏画布多大?我建议 400×400px,20×20 网格——桌面端和移动端都够用。
Q2: 蛇的移动速度?推荐 150ms/步,有挑战但不至于太快。
Q3: 游戏结束的交互?HTML modal 弹窗 + 重新开始按钮,比 alert() 好。
用户逐一确认。Agent 产出 tasks/prd-snake-game.md,核心内容:四条用户故事(移动控制、食物消费、碰撞结束、最高分持久化),八条验收标准(全部 checkbox 格式),非目标明确标注(不加难度曲线、音效、排行榜)。
因为没有跨服务改动和合规需求,跳过 /prd-to-spec,直接进入拆解。
8.13.2 第二步:/to-issues 拆解
/to-issues tasks/prd-snake-game.mdAgent 将 PRD 拆成四个 Issue,每个 Issue 的验收标准相互独立:
| Issue | 标题 | 验收标准 | 预估 |
|---|---|---|---|
| #1 | Canvas 渲染与蛇的初始状态 | 20×20 网格 + 绿色蛇 + 红色食物 | 20min |
| #2 | 方向键控制与 150ms 游戏循环 | 四方向移动 + 禁止反向 + nextDirection 缓冲 | 25min |
| #3 | 碰撞检测与食物系统 | 墙壁/自身碰撞 + 食物消费 + 随机生成不重叠 | 25min |
| #4 | 分数系统与游戏状态管理 | 当前分/最高分 + modal 弹窗 + localStorage 降级 | 20min |
用户确认拆分合理,四个 Issue 在本地 .autoresearch/issues/ 目录下生成。
8.13.3 第三步:/goal 逐个实现
/goal .autoresearch/issues/issue-001-snake-canvas.mdAgent 读取 Issue #1,分析项目结构(纯前端,无框架),生成 snake-game/index.html,包含 Canvas 和渲染函数。跑测试,验收标准逐条验证——网格可见 ✓,蛇初始位置正确 ✓。Issue #1 完成。
依次执行 #2、#3、#4。和第 4-7 章贪吃蛇实现不同的是,Goal Workflow 的实现过程少了一类问题:Agent 在 #2 中就实现了 nextDirection 缓冲机制——因为 /to-issues 拆解时,Agent 读 PRD 中的技术要求("键盘事件写入 nextDirection 缓冲"),直接写进了 Issue #2 的验收标准里。
四个 Issue 全部实现完毕,通过,约 6 分钟。
8.13.4 第四步:/review-it 审查
/review-itAgent 检测到分支上有未合入的 commit,运行 --mode branch,对比 origin/main...HEAD。审查发现两条:
发现 #1:
#3中食物随机生成逻辑在蛇身长度超过 200 格时(极端情况)会退化为线性扫描全网格——O(n²)。当前 20×20 网格不会触发,但可读性差。建议改为 Fisher-Yates 洗牌 + pick first。Auto-fix。发现 #2:
#4中loadHighScore()的 try-catch 只处理了SecurityError,没有处理QuotaExceededError——Firefox 隐私模式下setItem可能抛这个异常。手动确认修复。
用户确认修复 #2。Agent 修改代码,重新跑测试——全部通过。
8.13.5 第五步:/ship-it 交付
/ship-itAgent 执行:git add + commit → push → gh pr create → squash merge → comment → close Issue。约 40 秒走完。
贪吃蛇的完整功能档案留在仓库里:tasks/prd-snake-game.md(为什么做)→四个 Issue(每一步要验证什么)→ PR #43(代码变更)→ docs/issue#43.html(设计决策记录)。
跟前面六章比,Goal Workflow 的贪吃蛇开发全程约 15 分钟,比 autoresearch 的 3 分钟写 Issue + 12 分钟自动执行总共差不多。但人在每一步之间参与了四次——PRD 确认、Issue 拆分确认、审查修复确认、交付确认。每次参与花几秒钟,换来了每一跳的质量确认。
8.14 七种方法的同一个案例
同一个贪吃蛇,四种方法论的对比:
| 维度 | gstack(第 5 章) | superpowers(第 6 章) | autoresearch(第 7 章) | Goal Workflow(本章) |
|---|---|---|---|---|
| 人类参与 | 逐个阶段运行命令,约 2 小时 | 回答 5 个设计问题,约 5 分钟 | 写一个 Issue,约 3 分钟 | 每个步骤确认一下,约 8 分钟 |
| 流程驱动 | 人驱动(手动调用每个阶段) | Agent 驱动(自动触发 Skill) | 脚本驱动(全自动) | 人驱动(手动调用每个命令) |
| 覆盖范围 | 从想法到交付 | 从设计到代码 | 从 Issue 到合入 | 从想法到上线 |
| 控制粒度 | 粗粒度(Sprint 阶段) | 细粒度(Skill 自动触发) | 无控制(全自动) | 中粒度(每个命令确认一下) |
| 产出质量 | 高(角色全覆盖) | 中高(工程维度强) | 中高(依赖 Issue 质量) | 高(每个步骤有明确标准) |
| 最佳场景 | 从零到一的完整项目 | 中等复杂度的独立功能 | Issue 明确、可独立验证的功能 | 需要完整流程但保留控制权的项目 |
Goal Workflow 的参与时间比 autoresearch 长(约 8 分钟 vs 约 3 分钟),但每个参与点都有意义——PRD 生成后确认需求正确,Issue 拆解后确认拆分合理,审查通过后确认质量满意。这些确认不是流程冗余,是质量门禁。
和第 3-7 章的关系:
SDD(第 3 章)说"先规格、后代码",Goal Workflow 给了你两个生成规格的命令。SDD 的规格是人机合约,Goal Workflow 的 PRD/SPEC 不仅是人机合约,也是流水线步骤之间的合约——PRD 定义了 /to-issues 的输入标准,SPEC 定义了 /goal 的技术约束。
Ralph Loop(第 4 章)通过 completion promise 判断"做没做完"——Agent 自我声明。/goal 通过 Issue 验收标准判断——测试结果告诉你做没做完。前者适合验收标准就是一句话的简单任务,后者适合 checkbox 列表的结构化任务。
gstack(第 5 章)和 Goal Workflow 都是串行流程——七个 Sprint 阶段 vs 七个流水线步骤。核心区别在谁驱动。gstack 是角色驱动("你是一个产品经理"),Goal Workflow 是命令驱动("现在生成 PRD")。前者适合不知道标准流程的开发者,后者适合知道每一步该做什么、只需要工具加速的开发者。
autoresearch(第 7 章)是同一个作者的另一种设计哲学——脚本驱动,你写 Issue,脚本跑 Agent,评分,合入。Goal Workflow 是人驱动——你调命令,Agent 执行,你确认。前者追求自动化程度,后者追求控制力。
8.15 适用边界
Goal Workflow 是为中小型项目设计的。从功能规划到上线一条龙,每个步骤有明确的质量标准,不需要自己设计流程。PRD 和 SPEC 天然适合多人协同——它们是产品和研发之间、前端和后端之间、开发和审查之间的合约。
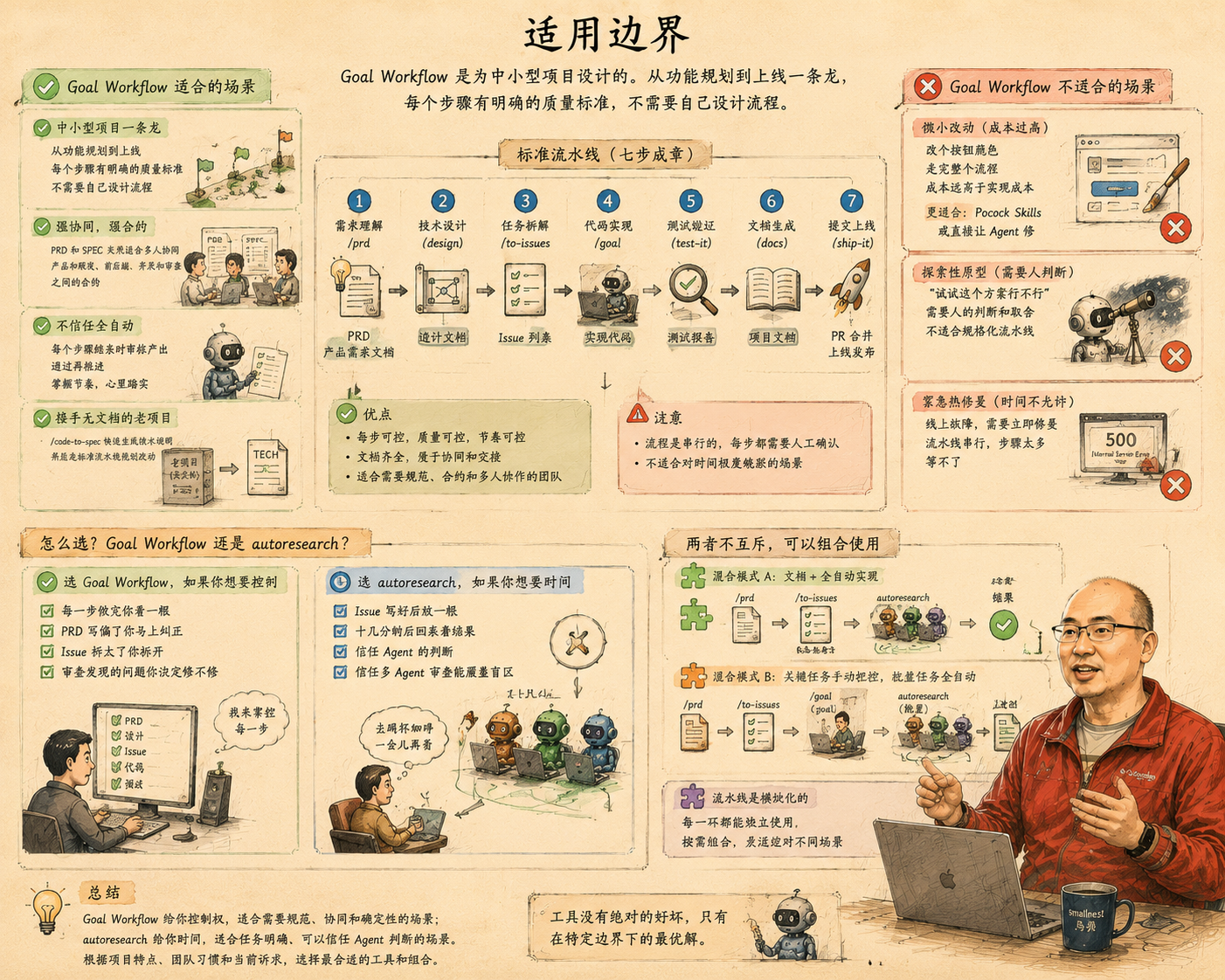
如果你不信任全自动——autoresearch 的"一觉醒来一排 merged"让你不安——Goal Workflow 就是给你的。每个步骤结束时审核产出,通过再推进。如果你接手了一个没有文档的老项目,/code-to-spec 快速生成技术说明,然后走标准流水线规划改动。
但它不是万能药。
改个按钮颜色走 /prd → /to-issues → /goal → /review-it → /ship-it,流程成本高于实现成本。Pocock Skills 或直接让 Agent 修更合适。探索性原型——"试试这个方案行不行"——需要人的判断,不适合规格化流水线。紧急热修复更不行——流水线是串行的,每步都要人确认,线上故障等不了。
最常被问到的问题:Goal Workflow 和 autoresearch 怎么选?
选 Goal Workflow,如果你想要控制。每一步做完你看一眼。PRD 写偏了你马上纠正。Issue 拆大了你拆开。审查发现的问题你决定修不修。
选 autoresearch,如果你想要时间。Issue 写好后放手,十几分钟后回来看结果。信任 Agent 的判断——信任它不会在验收标准上摇摆,信任多 Agent 审查能覆盖盲区。
两者不互斥。你可以用 /prd + /to-issues 生成 Issue,丢进 autoresearch 全自动实现。也可以用 /prd + /to-issues + /goal 手动实现前几个关键 Issue,再 autoresearch 批量跑剩下的。流水线是模块化的——每一环都能独立使用。
8.16 本章小结
把第 4-8 章放在一起看,五条路线对应五种研发组织模式。Ralph Loop 是循环自治——Agent 反复迭代到正确。gstack 是角色治理——二十三个虚拟角色覆盖质量全维度。superpowers 是技能触发——Agent 自动激活对的工具。autoresearch 是全自动流水线——人类只定义目标。Goal Workflow 是手动流水线——人类推一下,Agent 走一步,每一步的质量都经过人的确认。
没有高下之分。它们都在回答同一个问题:在 AI 能写代码的时代,人应该做什么?
autoresearch 的回答是:人定义目标,然后放手。Goal Workflow 的回答是:人定义每个阶段的"做好",然后确认。前者相信你一次能写清楚,后者相信你看了才知道对不对。
选哪个,取决于你对自己"能一次写清楚到什么程度"和"愿意参与多少步骤"的诚实判断。
下一章讲方法论对比与融合。前八章讲了八种方法论,各有优劣,互有重叠。第 9 章把八条路放在一起,帮你找到最适合自己的那条——或者把几条路拼在一起。
留言板
欢迎在此分享你的想法!评论通过 GitHub Issues 存储,需要 GitHub 账号登录。