第2章: Mattpocock Skills系统 —— 真正的工程,不是氛围编程
"Always take small, deliberate steps. The rate of feedback is your speed limit. Never take on a task that's too big."
步步为营,稳扎稳打。反馈的频率决定了你前行的极限。切忌贪大求全。
——David Thomas & Andrew Hunt, 《The Pragmatic Programmer》, 1999 年
从 Prompt-Driven 到 Skill-Driven——Prompt 消失在对话历史里,Skill 留在工具链里。要让这个主张从一句口号变成可以落地的体系,需要回答一个具体的问题:Skill 到底是什么?它长什么样?它是如何工作的?
本章深入分析 Matt Pocock 的 Skills 系统——目前社区中设计最精良、哲学最自洽的 AI Agent 能力单元框架之一。它不追求最大最全,但它对「什么是一个好的 Skill」这个问题的思考深度,远超同类项目。
在 GitHub 上,Pocock 用一句话概括了他的设计动机:"real engineering, not vibe coding。」(真正的工程,不是氛围编程。)它来自一个 TypeScript 讲师对软件工程本质的执念——在 AI 让任何人都能在十秒内生成一个可运行应用的年代,重新确认:工程化的价值是什么?
2026 年 2 月 3 日,Pocock 将日常使用 Claude Code 时积累的 Skills 整理成一个公共仓库,命名为 mattpocock/skills。仓库的描述行直白得不像一个"开源项目"——"Skills for Real Engineers. Straight from my .claude directory.」(为真正的工程师打造的 Skills。直接来自我的 .claude 目录。)没有发布会,没有精心策划的营销——只是把他每天都在用的东西公开了出来。
接下来的事情超出了所有人的预期。三个月内,这个仓库就冲到了约 97,000 个 GitHub Stars;到 2026 年 7 月 v1.1 发布前后,Stars 已突破 16 万,Fork 达到 13.8k+,Pocock 的 AI 工程 newsletter 订阅量同期稳定在约 60,000 人(作者自述数据)。
这里的关键词是时机,不是「网红程序员」。2026 年初,全世界的开发者正在经历同一件事:AI 编码工具的日常化。Claude Code、Codex、Cursor 已经进入大批工程师的日常工作流。但当开发速度暴涨的同时,代码质量的可控性在暴跌。整个社区在呼唤同一件东西——一套让 AI 编码"从能跑变成可信"的工程方法。Pocock 的 Skills 仓库恰好在这个时刻给出了一个精准的回答:不需要你改变整个流程,不需要你安装任何新工具,只需要把几个 Markdown 文件放到你的 .claude 目录里。
约 16 万 Star 的背后是这个问题的紧迫性本身。
2.1 概念起源:一个 TypeScript 讲师的工程执念
Matt Pocock 是 TypeScript 社区广受认可的教育者。他创立的 Total TypeScript 课程线被成千上万的开发者使用,他在 YouTube 和 Twitter 上的技术内容以清晰、深刻著称。但当他开始大量使用 Claude Code、Codex 等 AI 编码工具后,一个挥之不去的问题开始困扰他。

"AI Agent 让开发速度飞跃了一个数量级,但代码质量没有跟上。" 这不是某个人的抱怨,而是大量实践经验汇聚成的判断。Pocock 在多个场合描述了这种紧张:Agent 可以在几秒内生成几百行代码,但那些代码往往难以理解、难以测试、难以修改——在开发速度飞涨的同时,软件的可维护性历史性地塌陷了。
他在 Skills 仓库 README 中这样描述核心焦虑:"Approaches like GSD, BMAD, and Spec-Kit try to help by owning the process. But while doing so, they take away your control and make bugs in the process hard to resolve."(GSD、BMAD、Spec-Kit 这类方法试图通过接管流程来帮助你。但在这么做的同时,它们夺走了你的控制权,让流程中产生的 bug 难以定位和修复。)
这句话透露了他的设计哲学最底层的立场。GSD(Generalized Spec-Driven Development)、BMAD(Big Model Agile Development)、Spec-Kit 这类方法有一个共同特征:它们试图接管流程——定义好阶段、门控、输入输出格式,让 Agent 在这些约束中按部就班地工作。Pocock 承认这种方式有效,但他看到了一个代价:当你把控制权交给一个标准化的流程时,当流程出问题时你无法介入修复,因为流程本身就是一个黑箱。
他的解法是反其道而行之:不定义流程,只定义原子能力。每个 Skill 做一件事且只做一件事——调试就用 /diagnosing-bugs,写测试就用 /tdd,对齐需求就用 /grill-me。用户自己决定在什么时机用什么 Skill,而不是被一个预设的流水线推着走。工程师保留对流程的全部控制权,Skill 只是工具,不是规则。
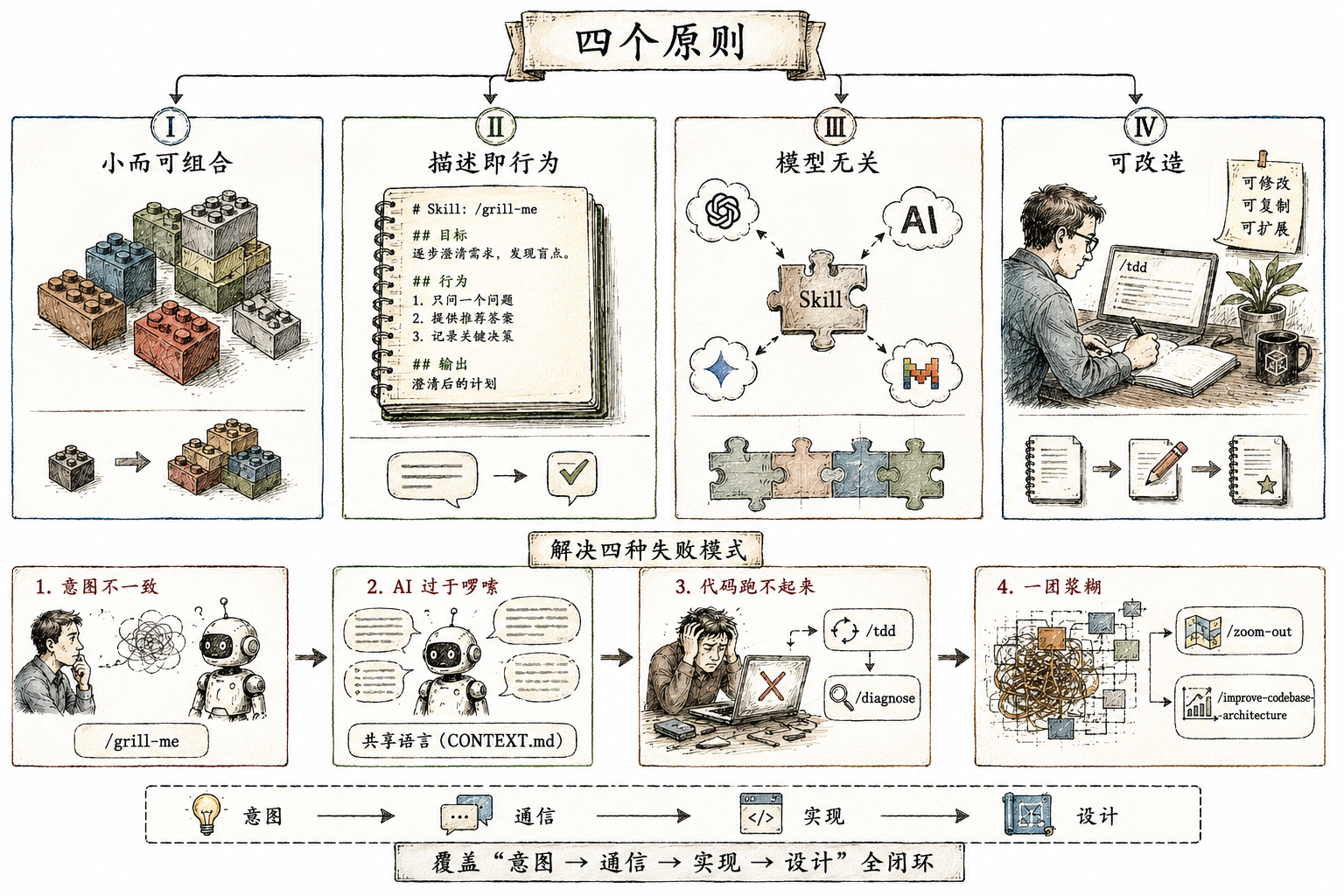
他把这个理念凝结为四个设计原则:
小而可组合。 每个 Skill 只解决一个问题。一个 Skill 修改一个 SKILL.md 文件,一个文件不超过几百行。复杂的工作流通过组合多个 Skill 实现,而非在单个 Skill 中堆积分支逻辑。这种设计使每个 Skill 都易于理解、易于改造、易于替换。
模型无关。 Skill 是用 Markdown 写的指令文件,不绑定任何特定模型的 API 或格式。同一个 Skill 可以工作在 Claude Code、Codex CLI、Cursor Agent、OpenCode 上——只要这些平台支持加载自定义指令。这种"写一次,到处跑"的开放性是 Pocock 刻意追求的设计属性。
可改造。 Skill 不是封装好的二进制包——它是一个 Markdown 文件,你可以打开、阅读、修改任何一行。Pocock 的原话是——"Hack around with them. Make them your own. Enjoy."(随意折腾。把它们变成你自己的。享受它。)
模型无关不是妥协。 很多方法论选择绑定特定模型以换取更强的控制力。Pocock 的选择相反——通过放弃平台绑定来换取通用性。这意味着某些高级特性(如 hooks、权限控制)无法在 Skill 层面实现,但换来的是一套可以在任何 Agent 工具上运行的开放标准。
这四条原则直接塑造了他接下来要解决的四个核心问题。
2.2 四个失败模式与四个修复
Pocock 在 README 中写道:"I built these skills as a way to fix common failure modes I see with Claude Code, Codex, and other coding agents."(我构建这些 Skill,是为了修复我在 Claude Code、Codex 和其他编码 Agent 身上反复看到的失败模式。)
他归纳出四种。每一种都配了一个来自经典软件工程文献的引语作为锚点——这个做法暗示 Skill 不是 AI 时代的发明,而是经典工程原则在 AI 时代的重新编码。
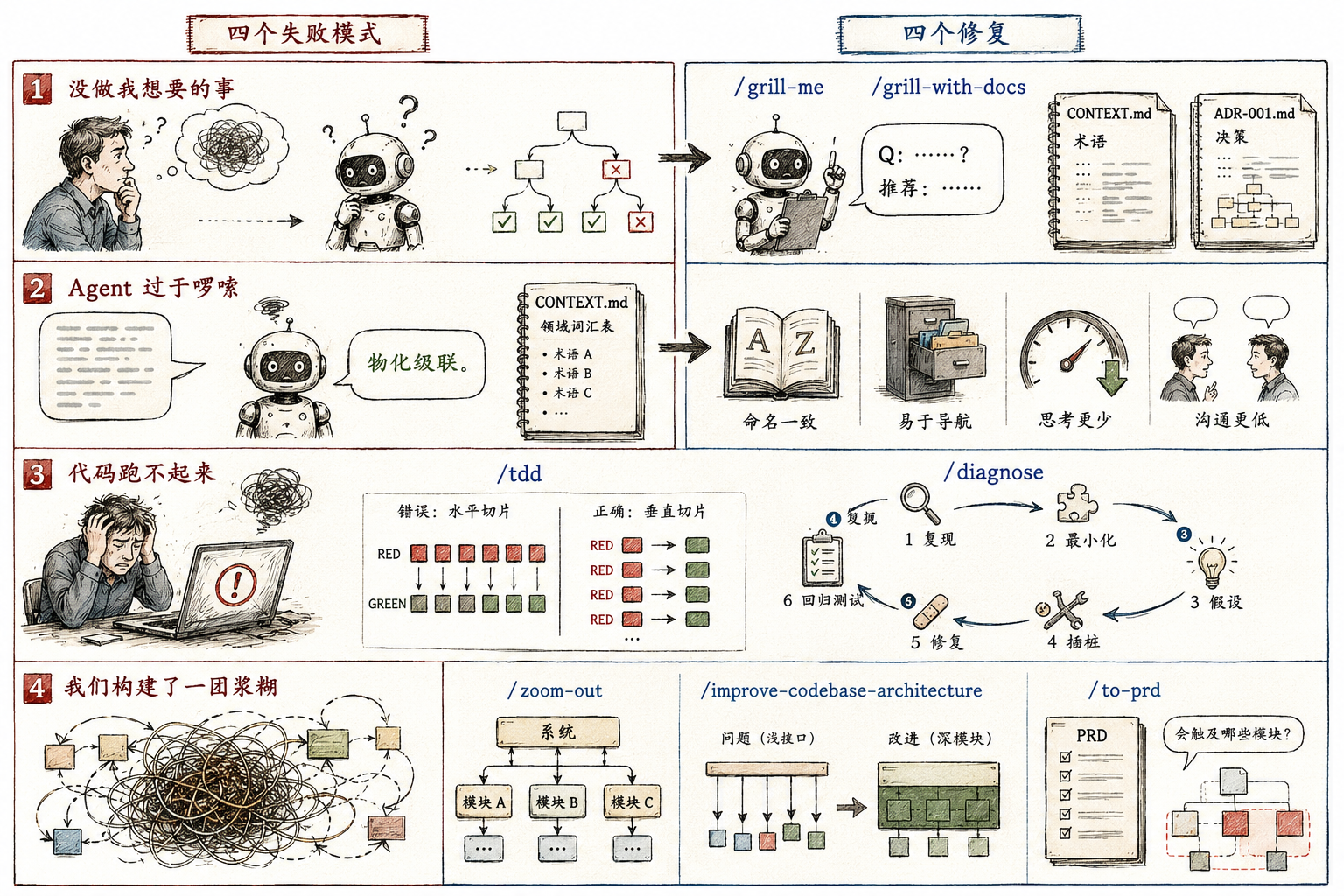
2.2.1 失败模式一:Agent 没做我想要的事
Pocock 引用的是《程序员修炼之道》(The Pragmatic Programmer)中的一句:"No-one knows exactly what they want."(没有人真正知道自己想要什么。)
这是软件开发中最古老的问题,也是最昂贵的。在传统开发中,解决方案是需求评审、原型、持续沟通——人类之间的对话。在 AI Agent 开发中,问题更加严重:你不只是在对话,你是在把指令输入一个没有生活经验、没有常识背景、对"合理"的判断高度不可预测的系统中。
Pocock 的修复是一个名为 /grill-me 的 Skill——也许是这个仓库中最有名的一个。它的行为可以概括为:"无休止地盘问我关于这个计划的每一个方面,一次只问一个问题。沿着决策树的每一个分支走到底,不跳过任何一个。对每个问题,给出你的推荐答案。"
这不是闲聊。这是一种结构化的、穷举式的需求澄清协议。你无法对一个"盘问"回答"差不多就行"。每个回答都在闭合一个选择分支,缩小歧义空间。一次只问一个问题——不被后续分支带偏,不跳步。对每个问题给出推荐答案——不把负担完全推给你,但你保留否决权。
/grill-with-docs 是这个 Skill 的增强版。它做同样的事,但额外做了两件关键的记录工作:一是将讨论中产生的术语新定义写入 CONTEXT.md(领域共享语言文档),二是将任何不可逆的架构决策记录为 ADR(Architecture Decision Record)。这两个动作本身,就是解决下一个失败模式的关键。
2.2.2 失败模式二:Agent 过于啰嗦
Pocock 引用的是 Eric Evans《领域驱动设计》中的话:"With a ubiquitous language, conversations among developers and expressions of the code are all derived from the same domain model."(有了通用语言,无论是开发者之间的日常交流,还是代码的具体实现,就都建立在同一个领域模型之上了。)
在传统项目中,开发团队和领域专家之间天然存在语言鸿沟——你说"付款确认",他理解的是"扣款成功"还是"订单确认"?Pocock 指出,在和 AI Agent 协作时,同样的问题以一种新的形式出现了:Agent 被丢进一个项目,没有被教过这个项目用什么词、怎么理解这些词。它只能靠自己推测。结果?"它们用 20 个词来说明一个只需要 1 个词就能表达的概念。"(They use 20 words where 1 will do.)
修复手段是一份叫做 CONTEXT.md 的文件——项目的领域词汇表。Pocock 举了一个真实的例子:在他自己的 course-video-manager 仓库中:
修改前: "There's a problem when a lesson inside a section of a course is made 'real' (i.e. given a spot in the file system)"
修改后: "There's a problem with the materialization cascade"
"Materialization cascade"(物化级联)是一个团队内部定义的术语——一旦被记录在 CONTEXT.md 里,Agent 每次读取项目上下文时就能理解它,不再需要用一句半的篇幅来解释同一个概念。这个节省是复利的:一次定义,此后每次会话都受益。
Pocock 对共享语言的价值做了四点归纳,总结在他 README 中的一个提示框中:
- 变量、函数和文件的命名保持一致——Agent 使用的是共享语言中的词
- 代码库更易于导航——因为一切遵循同一套命名逻辑
- Agent 在"思考"上消耗的 token 更少——它能用领域术语做精简的内部推理
- 人类与 Agent 之间的通信成本持续下降——每次会话不再需要重新"教"它项目里的词
共享语言解决的不只是啰嗦问题。它解决的是知识的外部化与持久化——让项目知识不再只存在于你的记忆里,而是可以被任何人在任何会话中接入的结构化文档。正如他所说:"这可能是整个仓库中最酷的一项技术。"(It might be the single coolest technique in this repo.)
2.2.3 失败模式三:代码跑不起来
第三个失败模式对应第 1 章中 antirez 工作方式的核心原则:「审查 AI 生成的每一行代码。」
Pocock 再次引用《程序员修炼之道》:"Always take small, deliberate steps. The rate of feedback is your speed limit. Never take on a task that's too big."(步步为营,稳扎稳打。反馈的频率决定了你前行的极限。切忌贪大求全。)
即使你和 Agent 对齐了需求、"完成了"共同语言的建设——它产出的代码仍然可能跑不起来。可能是一个边缘情况没处理,可能是逻辑假设错误,可能是几个模块之间的协动出了问题。这本质上是反馈回路缺失。没有验证的代码,是猜测。
Pocock 提供了两个专门的 Skill 来弥补这一点。
/tdd——测试驱动开发。 这个 Skill 包含了一整条精心设计的 TDD 指南:红-绿-重构循环(v1.1 起重构阶段并入 /code-review,TDD 本体瘦身为红-绿)、正确测试和错误测试的详细示范(详见 tests.md)、Mock 使用指南(详见 mocking.md)。其中最有价值的洞见之一是 "反模式:水平切片"的警告。
水平切片的意思是:先写完所有测试,再写完所有实现。Pocock 直截了当地说:别这么做。(DO NOT write all tests first, then all implementation.)
它列出的原因很具体:
- 批量写的测试验证的是"想象中的行为",而不是"真实的行为"
- 你最终测试的是数据结构和函数签名,而不是用户看到的行为——测试过拟合于实现
- 测试对真实的变化变得麻木——行为坏了测试却通过,行为没变测试反而失败
- 你跑得比你看到的信息更远——在没理解实现前就对测试结构做了不可逆的承诺
正确的做法是 "垂直切片"——一个测试,一个实现,循环往复。 每次循环都基于上一轮学到的新信息。因为刚刚写完代码,所以你知道精确地知道什么行为重要,以及怎么验证它。Pocock 用一个简单的图表表达:
错误 (水平切片):
RED: test1, test2, test3, test4, test5
GREEN: impl1, impl2, impl3, impl4, impl5
正确 (垂直切片):
RED → GREEN: test1 → impl1
RED → GREEN: test2 → impl2
RED → GREEN: test3 → impl3
...第一个测试是"曳光弹"(tracer bullet)——证明整条路径从头到尾能走通。此后每一个新增的测试都回应上一个实现的产物,形成紧密的反馈回路。
/diagnosing-bugs——系统化调试。 这六个阶段的循环是:复现(reproduce)→ 最小化(minimise)→ 提出假设(hypothesise)→ 插桩(instrument)→ 修复(fix)→ 回归测试(regression-test)。
Pocock 特意强调了第六步——修复完成后必须把复现的场景转化为回归测试,否则同一个 bug 迟早会回来。这种设计方式使调试行为本身也变成了知识积累——每修一个 bug,项目的测试资产就多一条。
2.2.4 失败模式四:我们构建了一团浆糊
这是四个失败模式中最深刻的一个,也是 Pocock 引用了两位经典作者来压阵的。
Kent Beck《解析极限编程》: "Invest in the design of the system every day."(每天都要花时间打磨系统架构。)
John Ousterhout《软件设计的哲学》: "The best modules are deep. They allow a lot of functionality to be accessed through a simple interface."(最好的模块是深的——大量的功能通过简单的接口访问。)
问题描述直指痛处:"Most apps built with agents are complex and hard to change. Because agents can radically speed up coding, they also accelerate software entropy."(大多数用 Agent 构建的应用复杂且难以修改。因为 Agent 能极快地加速编码,它们也在加速软件的熵增。)Agent 能极快地加速编码,因此也在加速软件的熵增。代码库的复杂化速度超过了人类开发者驯化它的速度。
Pocock 的修复不止一个 Skill,而是一套植入在每个 Skill 中的"关心设计"的立场。
/zoom-out 的做法最简单但最有力。当一个 Agent 在修改你不熟悉的代码时,你对它说 /zoom-out,它会退后一步:不和你说实现细节,而是告诉你——这里的系统全貌是什么?有哪些模块?它们如何协作?使用项目中的领域词汇来描述。实际上就是要求 Agent 用 CONTEXT.md 中的语言给你画一张系统的"地图"。
/improve-codebase-architecture 是修复"一团浆糊"的主力武器。它会系统性地扫描代码库并生成一份 HTML 报告——用可视化的框图展示每个架构问题的前后对比。报告使用 Ousterhout 的"深度模块"术语来诊断——接口是否相对于实现太浅?将复杂度集中到深模块后面。用"删除测试"来判断一个模块是否在"挣自己的位置"——删除它,如果复杂度消失了(而不是散落到 N 个调用者身上),说明它就是个"透传"模块。
Pocock 建议每隔几天运行一次——不是因为它每次都有新发现,而是"持续投资设计"本身就是防止架构退化的必要行为。
/to-spec 也是设计感的体现——在创建规格(spec)之前,它会先问你:这个修改会触及哪些模块?不是问"做什么功能",而是问"影响什么地方"。这让 Agent 和用户在进行具体讨论之前,先在"我们改动哪个模块"这个核心上达成共识。
2.3 安装与初始化:30 秒上手
Skills 系统的"零依赖"设计意味着它的安装不是"装一个工具",而是"复制几个 Markdown 文件"。
安装命令:
npx skills add mattpocock/skills这个命令运行后,一个交互式界面会让你选择两件事:安装哪些 Skill(全部或按需勾选),以及安装到哪些 Agent 平台(Claude Code、Codex、Cursor 可多选)。选择后,选中的 SKILL.md 文件被复制到对应平台配置目录下(如 Claude Code 对应 ~/.claude/skills/)。
Pocock 特别强调:务必勾选 /setup-matt-pocock-skills。 安装完成后,在 Agent 中运行这个 Skill。它会依次询问三个配置问题,建立项目与本地的连接:
- 选择 Issue 追踪器。 GitHub Issues、Linear,还是本地
.scratch/目录?这决定了/to-tickets、/to-spec、/triage等 Skill 的读写目标。 - 定义 Triage 标签。 在进行 Issue 分诊(
/triage)时,使用哪些标签来标记 Issue 的状态?这些标签必须与项目的真实标签体系对应。 - 选择文档保存位置。
CONTEXT.md、ADR、PRD 等文档该放置的项目路径。
这三个问题的答案被写入 .claude/config/ 下的配置文件,成为所有 Skill 的共享上下文。套用第 1 章中的分类,这个字段的结构化信息就是系统的 Harness 层——项目别名、命名约定、状态定义。
安装完成后,你在 Agent 中输入 / 就能看到已经可用的新版 Skill 命令。不需要重新启动,不需要环境变量,不需要 API key。Pocock 对这个设计理念的概括是:"Bam - you're ready to go."(砰——可以开工了。)
2.4 运行机制:一个 Markdown 文件如何改变 Agent 的行为
到目前我们已经讨论了 Skill 的定义与设计。接下来回答一个更底层的问题:一个 Markdown 文件,到底怎么变成 Agent 的行为?
2.4.1 SKILL.md 的文件结构
每个 Skill 是一个独立的目录,目录下必须有且仅有一个文件:SKILL.md。没有任何其他技术依赖。
SKILL.md 的结构分为两层。第一层是 YAML 前置元数据(frontmatter):
---
name: skill-name
description: One-line summary of what the skill does and when to use it.
---name 是 Skill 的唯一标识,也是用户调用的斜杠命令名称——name: grill-me 对应 /grill-me。
description 承担两项功能:一是给用户看,描述这个 Skill 做什么;二是给 Agent 的自动匹配器看——Agent 运行时扫描所有已加载的 Skill 的 description 字段,当用户当前输入语义上与某个 description 匹配时,自动触发该 Skill。
第二层是 Markdown 正文——这就是 Agent 收到的实际指令。它不是一份供人类阅读的 API 文档,而是一份写给 Agent 的行为指令——用的是第二人称,现在是命令式,语气是一个领域专家对一个刚入职的新手程序员做 onboarding——准确、密集、不废话。
以 /grill-me 为例,它的正文只有一句话:
Interview me relentlessly about every aspect of this plan until we reach a shared understanding. Walk down each branch of the design tree, resolving dependencies between decisions one-by-one. For each question, provide your recommended answer. Ask the questions one at a time. If a question can be answered by exploring the codebase, explore the codebase instead.
五句话,没有一句浪费:目标(relentlessly interview)、方法(walk down each branch)、具体操作(one-by-one)、附带责任(provide recommended answer)、约束(validate against codebase)。这个 Skill 的行为完全由这五句话定义——简练到没有留任何歧义空间。
更复杂的 Skill 使用 "渐进式信息披露"(Progressive Disclosure) 模式:核心指令写在 SKILL.md 中,更详尽的参考资料放在同级目录下的其他文件里(如 tests.md、mocking.md、LANGUAGE.md),Agent 在需要时通过文件引用来获取更多上下文。这样 Volatile 的知识(指令、核心规则)和持久化的知识(详细示范、术语解释)分离,Skill 文件本身保持精悍。
2.4.2 Skill 的触发与运行
一次 Skill 调用经历了四个步骤:
1. 发现(Discovery): Agent 启动时扫描配置的 Skill 目录,读取所有 SKILL.md 文件的前置元数据,建立 Skill 索引。
2. 匹配(Matching): 当用户发出指令时,Agent 有三种触发 Skill 的方式:显式调用——用户键入了斜杠命令(如 /diagnosing-bugs),直接执行该 Skill;自动匹配——Agent 判断用户的输入语义上与某个 Skill 的 description 匹配,自动加载该 Skill 的指令;Skill 内引用——一个 Skill 的指令中引用了另一个 Skill 的行为(如 /grill-with-docs 的行为是 /grill-me 的指令加上额外的文档处理逻辑)。
3. 加载(Loading): Agent 将 SKILL.md 的正文注入当前会话的上下文——就像一个虚拟的"项目文档"被读入对话一样。Skill 之间不共享上下文,每个 Skill 在独立的指令空间中执行,避免交叉污染。
4. 兼容性(Compatibility): Skill 指令使用纯自然语言,不调用任何特定 Agent 平台的内置 API。两个不同的 Agent 工具对同一个 SKILL.md 的解释可能略有不同——因为模型在理解自然语言时会产生细微差异——但核心行为是一致的。这种"平台独立的自然语言编程"是 Skills 系统能在 Claude Code、Codex、Cursor、OpenCode 之间自由移植的根本原因。
2.5 实战:用 Skills 系统完成一次开发流程
逐个解释 Skill 的原理是基础,但把多个 Skill 串起来跑一条完整链路更能说明问题。
下面以一个具体的微型任务为例:用纯前端技术做一个在浏览器中可玩的贪吃蛇网页游戏——方向键控制蛇的移动,吃食物变长得分,撞墙或撞到自己则游戏结束。

2.5.1 第一步:对齐需求(/grill-with-docs)
这个任务看起来简单——贪吃蛇的规则人人知道——但落到工程实现,立刻冒出一堆需要闭合的决策分支。网格多大?蛇多快?分数怎么算?游戏结束后怎么办?食物怎么生成?
启动 /grill-with-docs:
用户: /grill-with-docs 做一个贪吃蛇网页游戏。方向键控制蛇移动,
吃食物后蛇变长、分数增加。撞墙或撞到自己则游戏结束。
纯前端 HTML/CSS/JS 单文件实现。Agent 一次只问一个问题,逐个闭合决策分支:
Q1: 游戏网格你期望多大?我推荐 20×20——适合桌面端,移动端也不会太小。每个格子 20px,整个画布 400×400。
用户同意。
Q2: 蛇的初始移动速度?我推荐 150ms/步——有挑战但不至于太快。如果要加难度曲线(每吃 5 个食物加速 10ms),现在也可以预留。
用户选择先做固定速度 150ms,难度曲线以后再考虑。
Q3: 分数系统怎么设计?每个食物 10 分,还是递增?最高分要不要用 localStorage 存下来?
用户确认:每个食物 10 分,最高分用 localStorage 持久化,刷新后保留。
Q4: 蛇的初始方向?我建议初始状态为静止——玩家按下第一个方向键后蛇才开始移动。避免玩家还没准备好蛇就撞墙了。
用户同意。
Q5: 如果用户快速连续按方向键(比如当前向右,在 150ms 内快速按了下再按左),应该怎么处理?我建议用
nextDirection缓冲——键盘事件只写入缓冲变量,游戏循环每次读取后才同步到实际方向。这样可以吃掉多余的输入,防止蛇反向移动。
用户同意。这个交互细节如果不在这步澄清,后面调试会极其痛苦。
对话结束后,Agent 自动执行了两个写入操作:
- 将新产生的术语(
GameState、nextDirection缓冲机制、网格坐标约定{x, y}、食物随机生成算法spawnFood())写入CONTEXT.md - 将"选择 nextDirection 缓冲而非直接写入方向"这个不可逆决策记录为 ADR
澄清对话本身是瞬态的,但对话的产物——CONTEXT.md 和 ADR——是持久的。下一次任何人(或任何 Agent)打开这个项目,不需要重新解释"为什么用 nextDirection 而不是直接改方向"。
2.5.2 第二步:生成 PRD(/to-prd)
/grill-with-docs 结束时,Agent 已经积累了足够的信息:核心行为、约束边界、容错策略。现在运行 /to-prd:
/to-prd不需要再问问题——它直接从刚刚的对话中提取信息,合成一个结构化的 PRD 并提交到 Issue 追踪器中。
PRD 被提交为一个 Issue,包含:问题陈述、用户故事(四条——蛇的移动控制、食物消费与得分、碰撞与游戏结束、最高分持久化)、验收标准(十六条,全部可自动化验证)、非功能需求(150ms 循环间隔、首次渲染 < 500ms、零外部依赖)。
2.5.3 第三步:拆分为独立 Issue(/to-issues)
这个 PRD 自然包含四个可独立推进的任务。/to-issues 读取 PRD Issue,将其拆分为四个独立 Issue:
Issue #12: 创建游戏画布与渲染层——初始化 20×20 Canvas,实现
drawGrid()、drawSnake()、drawFood()Issue #13: 实现蛇的移动与键盘控制——
gameState状态对象、方向缓冲nextDirection、150ms 游戏循环、键盘事件绑定Issue #14: 碰撞检测与食物系统——墙壁碰撞、自身碰撞、食物消费、随机生成
Issue #15: 分数系统与游戏状态管理——当前分数/最高分显示、游戏结束弹窗、重新开始按钮、localStorage 降级
每个 Issue 都包含独立的验收标准,确保任何一个都可以被检出、实现、测试、合入,而不阻塞其余三个。注意这里的依赖关系:Issue #13 依赖 #12(画布必须先存在),#14 依赖 #13(碰撞检测需要蛇的坐标),#15 依赖 #14(游戏结束触发分数判定)。
2.5.4 第四步:TDD 实现第一个 Issue(/tdd)
/tdd 的详细机制已在 2.2.3 中展开。这里用一个具体迭代来展示垂直切片如何运作。
启动 /tdd,选择 Issue #12:
Agent: 我先写第一个测试——验证画布初始化后能渲染一个空网格。
Test (RED):
it('renders a 20x20 grid on canvas', () => {
const canvas = initGameCanvas();
expect(canvas.width).toBe(400);
expect(canvas.height).toBe(400);
const ctx = canvas.getContext('2d');
// 验证 drawGrid 调用后 canvas 不为空白
drawGrid(ctx);
const imageData = ctx.getImageData(0, 0, 400, 400);
expect(isCanvasBlank(imageData)).toBe(false);
});
// FAIL: initGameCanvas is not defined
Agent: 现在写最小实现让测试通过。
Impl (GREEN):
function initGameCanvas(): HTMLCanvasElement {
const canvas = document.createElement('canvas');
canvas.width = 400;
canvas.height = 400;
return canvas;
}
// PASS然后写第二个测试:蛇的初始渲染——长度 3,位于网格中央,水平排列——RED → GREEN。第三个测试:食物渲染为红色方块,位置在蛇身范围之外——RED → GREEN。
三个垂直切片完成后,Issue #12 已经有了三条可验证的行为保证。Agent 继续完成 drawGrid()、drawSnake()、drawFood() 函数,每条都在其对应的测试通过后合并到实现中。
2.5.5 第五步:调试一个失败的测试(/diagnose)
生成的 html 直接里浏览器打开没有启动游戏,原因是引入的 javascript 方式的问题,本地以文件的方式打开有问题。不过一开始的时候我们不知道原因,我们可以使用这个斜杠命令诊断这个问题。
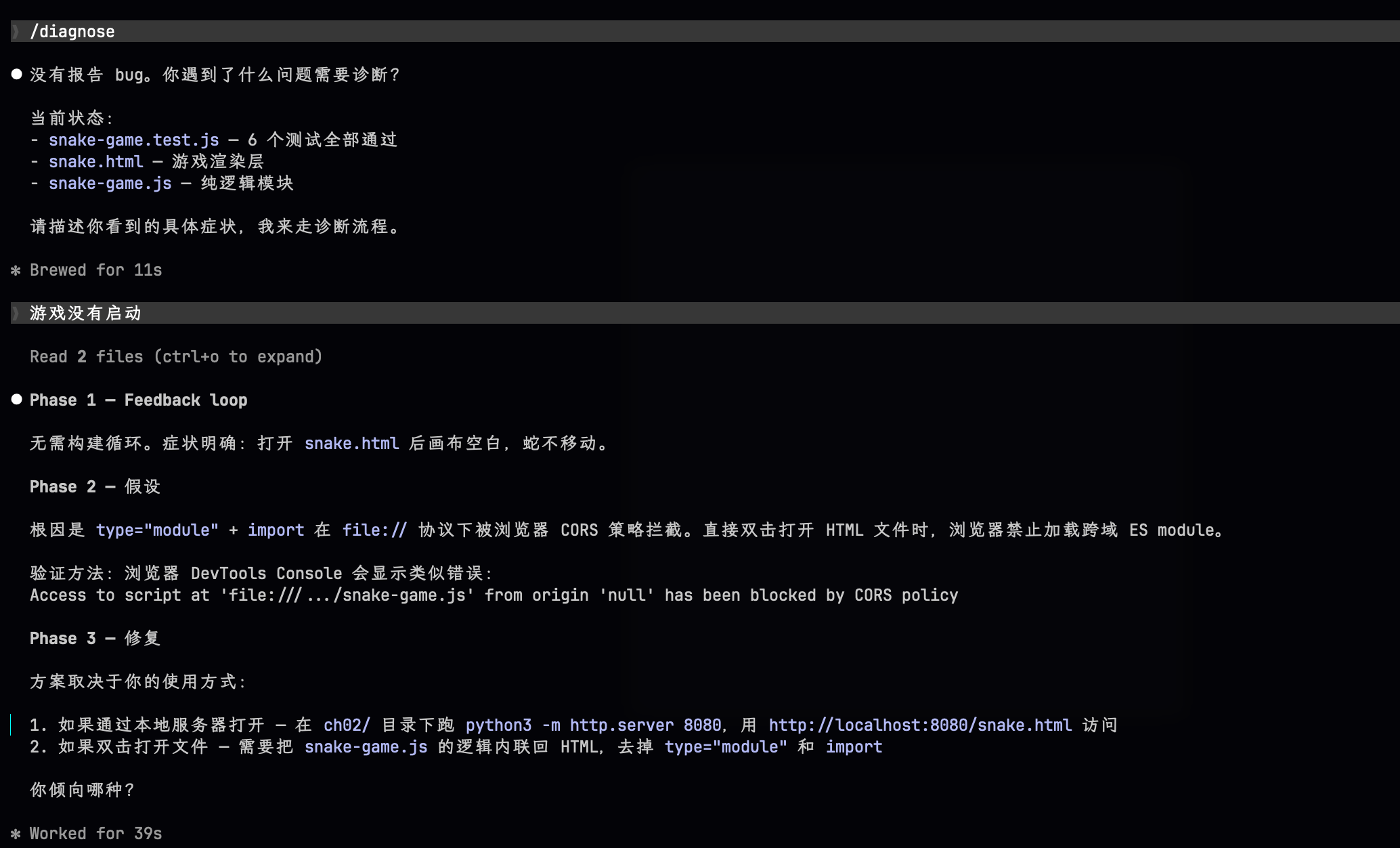
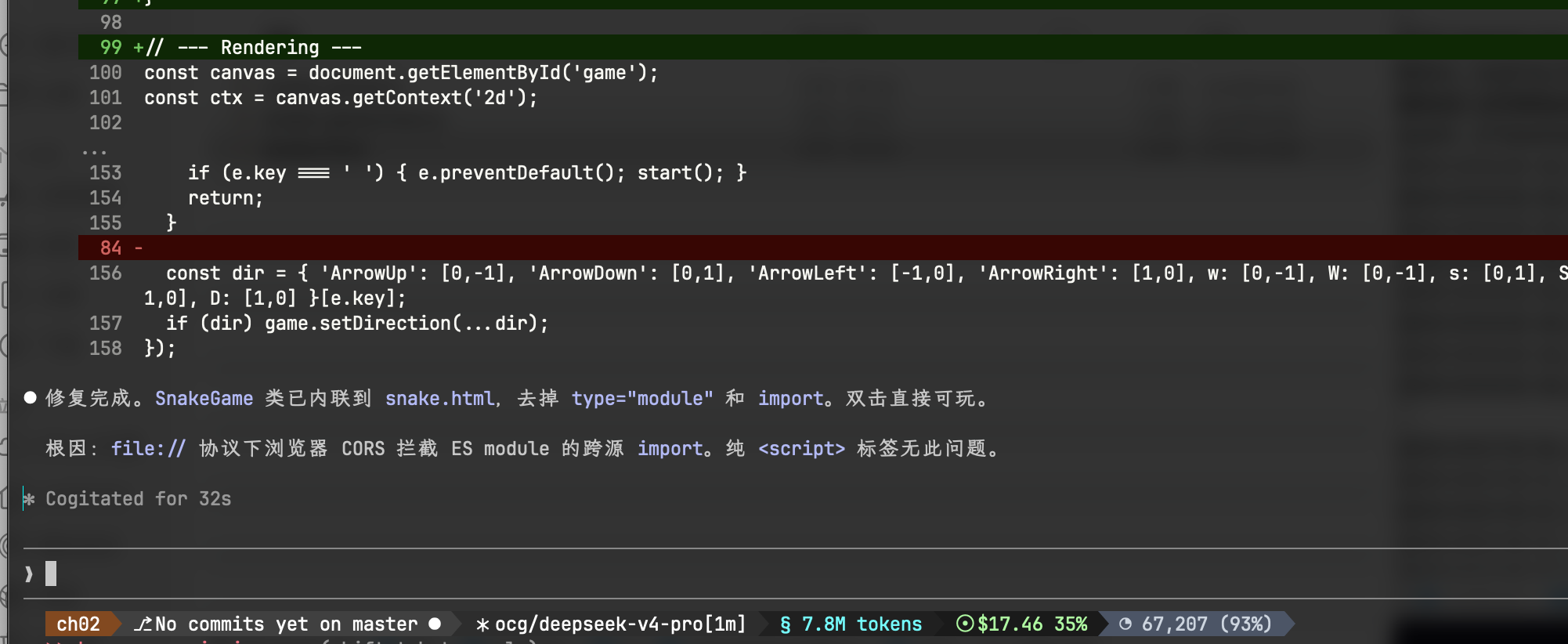
它给出了两个修复方案,我选择第二种,最后它修复完成:
2.5.6 第六步:理解陌生代码(/zoom-out)
Issue #14 需要实现碰撞检测和食物系统,但接手这个任务的开发者(或 Agent)对前面已经写好的游戏循环和状态结构不熟悉。
启动 /zoom-out:
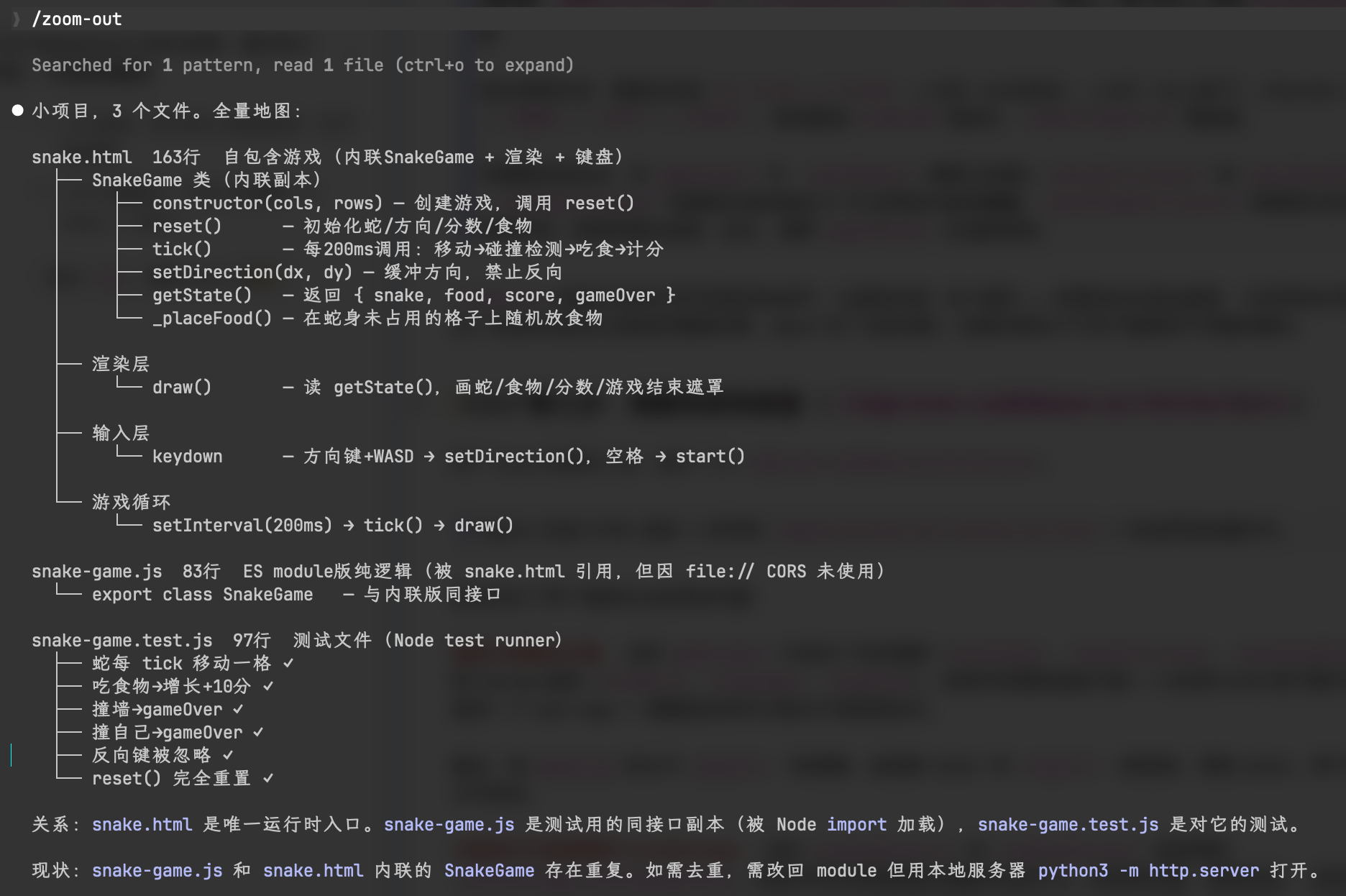
/zoom-out 的输出没有任何代码级别的细节。它提供的是一张"地图"——你要改的东西在哪里、它和其他东西的关系、用这个项目的语言怎么描述你要做的事。Agent 有了这张地图,后续的修改才不至于偏离到不该碰的模块。
貌似没有更新卡片和提交代码的 skill,所以我使用我开发的 ship-it 提交代码给关闭卡片。
2.5.7 第七步:周期性架构检查(/improve-codebase-architecture)
四个 Issue 全部合入后,运行一次 /improve-codebase-architecture。
Agent: 生成 HTML 报告 → 另存至
/tmp/architecture-review-xxx.html→ 自动用浏览器打开。
报告找出了两个值得关注的架构问题:
渲染与逻辑未分离。 当前 gameLoop() 中混合了状态更新(moveSnake、checkCollision、checkFoodCollision)和 Canvas 绘制(drawGrid、drawSnake、drawFood)。如果未来要换渲染方案——比如用 DOM 格子替代 Canvas,或者加一个 mini-map——逻辑层应该可以独立于渲染层运行。
建议:将 gameLoop 拆分为 update()(纯逻辑,返回新 state)和 render()(纯绘制,读取 state)。两个函数各自独立可测试。
分数持久化直接操作 localStorage。 当前 saveHighScore() 和 loadHighScore() 直接调用 localStorage.setItem/getItem。如果未来有其他数据也需要本地持久化(如游戏设置、成就系统),当前模式会导致散落的 localStorage 调用。
建议:提取一个 StorageAdapter 接口(get、set、remove 三个方法),让分数模块和其他模块都依赖接口而非直接操作 localStorage。
Pocock 建议每隔几天运行一次这个 Skill。在上面的例子中,它发现的问题不在任何一个 Issue 的实现中——它们是跨模块的架构问题,只有在四个模块全部上线后才能浮现。这就是"一团浆糊"的典型来源:个体的修改各自合理,但组合起来产生了意料之外的耦合。/improve-codebase-architecture 的作用就是把这种耦合从隐式变为显式。
2.5.8 一条完整链路的意义
从 /grill-with-docs → /to-prd → /to-issues → /tdd → /diagnose → /zoom-out → /improve-codebase-architecture,七步走了一个闭环:
对齐意图 → 结构化需求 → 可并行分解 → 垂直切片实现 → 系统化调试 → 上下文导航 → 架构审计它的模式不是"阶段一 → 阶段二"的流水线,而是在需要的时间点插入正确的行为。一个 Skill 只做一件事——用 Pocock 的话——它是小而可组合的——且这一步结束后的产物自动变成下一个 Skill 的输入。
2.6 两个值得单独讨论的 Skill
上述四个失败模式中讨论了 /grill-me、/tdd、/zoom-out、/improve-codebase-architecture 等 Skill。还有两个 Skill 值得单独用一节篇幅展开——不是因为它们在体系中"更大",而是它们各自触及了 AI 软件工程的两个根本性问题:调试知识的可传递性和会话边界的可交接性。
2.6.1 /diagnose:调试不是「看代码」,是「建反馈回路」
2.2.3 简要介绍了 /diagnose 的六阶段循环。但那只是外壳。打开它的 SKILL.md,第一段话就会让有经验的调试者沉默:
Phase 1 — Build a feedback loop
This is the skill. Everything else is mechanical. If you have a fast, deterministic, agent-runnable pass/fail signal for the bug, you will find the cause — bisection, hypothesis-testing, and instrumentation all just consume that signal. If you don't have one, no amount of staring at code will save you.
Spend disproportionate effort here. Be aggressive. Be creative. Refuse to give up.
(阶段一 —— 建立反馈回路。这就是 Skill 本身。 其他的一切都是机械的。如果你有一个快速、确定性、Agent 可运行的"通过/失败"信号来判断 bug,你就会找到原因——二分法、假设检验、插桩都在消费这个信号。如果你没有这个信号,看再多代码也救不了你。在这一步投入不成比例的精力。要主动、要有创造力、要拒绝放弃。)
"This is the skill." 指向的不是六阶段循环,也不是假设生成和验证——而是建立反馈回路。Pocock 在此拆解了一个关键洞察:调试的价值不来源于人的判断力,而在于一个可以自动判决"问题是否还在"的信号。后面五个阶段只是机械地消费这个信号。
这句话对 AI 时代的意义比它看起来更重。传统调试依赖一个资深工程师的直觉——他看到一段代码就知道"这里不太对"。但 Agent 没有直觉。Agent 只有循环——反复运行一段代码、检查输出、比对抗预期。这恰恰是 Agent 最擅长的事。但前提是:你得给它一个能跑出结论的循环。
/diagnose 列出了九种构建反馈回路的方式,按推荐顺序排列:
- 失败的测试——能触及 bug 的任何接缝处的测试(单元/集成/E2E)
- Curl/HTTP 脚本——对 dev server 的请求-响应验证
- CLI 命令——用固定输入运行,diff stdout 与已知正确的快照
- 无头浏览器脚本——Playwright/Puppeteer 驱动 UI,断言 DOM/控制台/网络
- 回放已捕获的 trace——把真实请求或事件日志保存到磁盘,在隔离环境中重放
- 一次性的 harness——启动系统的最小子集(一个服务 + mock 依赖),单个函数调用触发 bug 路径
- 属性/模糊测试——如果 bug 是"有时输出不对",跑 1000 次随机输入找失败模式
- 二分 harness——如果 bug 出现在两个已知状态之间,自动化
git bisect run - 差分回路——相同的输入跑老版本和新版本,diff 输出
- 人机回路 bash 脚本——如果必须由人点击,用结构化脚本驱动人工操作、把输出喂回给 Agent
这个清单的价值不只是"方法多"——它的排序本身就是一条经验曲线:越往上越自动化、越可作为"裁定器"复用在后续所有调试活动中。每向上爬一级,你的调试体系就少一分对人的依赖。
/diagnose 还要求把反馈回路当作产品来迭代——有了回路之后,能不能让它更快?更锐利(断言精确症状而不是"没 crash")?更确定性(固定时间、种入随机种子、隔离文件系统、冻结网络)?一个 30 秒的 flaky 循环几乎不比没有循环好;一个 2 秒的确定性循环是调试超级武器。
命令式的另一面是禁止在没有回路时进入假设阶段。/diagnose 在这个点上的措辞不留余地:"Do not proceed to Phase 2 until you have a loop you believe in."(不建立你确信的反馈回路,就不要进入第二阶段。)
这六阶段的完整流程形成了一个严密的闭环:
Build Loop → Reproduce → Hypothesise → Instrument → Fix + Regression → Cleanup + Post-mortem其中 Phase 3 的假设生成有一个重要的约束:一次生成 3-5 个有排序的假设,每个假设必须是可证伪的("如果 X 是原因,那么改变 Y 会让它消失,改变 Z 会让它更糟糕")。单假设锚定在第一个灵感上——一个老调试者的直觉陷阱。
Phase 5 的回归测试要求也超出了常规实践:"在写修复之前先写回归测试——但前提是存在一个正确的接缝。" 如果当前架构产生不了正确的测试接缝,说明这个 bug 揭示了架构问题——应当记录并移交 /improve-codebase-architecture。
Phase 6 的收尾也同样精准:原始复现消失、回归测试通过、所有 [DEBUG-xxx] 探测代码用 grep 前缀一键清理、一次性原型删除、正确的假设被写入 commit message。最后一条——把"为什么"写进 commit——是知识的固化。下一次有人读这个 commit(包括 Agent),不需要重新推演推理链条。
/diagnose 最有价值的不是它的步骤多精密,而是它把调试从一种"资深工程师的直觉"转化为一种系统化的协议。这个协议可以被传授、被遵循、被验证——这正是 Skill 哲学的核心:把隐性知识外化。
2.6.2 /handoff:Agent 会话不是永恒的
如果说 /diagnose 解决的是"一个 session 内的反馈回路",那么 /handoff 解决的是"两个 session 之间的信息传递"。它的全部指令只有六句话,但每句话都指向 AI 开发流程中一个被严重低估的问题:
Write a handoff document summarising the current conversation so a fresh agent can continue the work. Save to the temporary directory of the user's OS — not the current workspace.
Include a "suggested skills" section in the document, which suggests skills that the agent should invoke.
Do not duplicate content already captured in other artifacts (PRDs, plans, ADRs, issues, commits, diffs). Reference them by path or URL instead.
Redact any sensitive information, such as API keys, passwords, or personally identifiable information.
If the user passed arguments, treat them as a description of what the next session will focus on and tailor the doc accordingly.
(写一份交接文档,总结当前对话,让一个新的 Agent 可以继续工作。保存到用户操作系统的临时目录——不是当前工作区。在文档中包含一个"建议的 Skill"部分,列出下一个 Agent 应该调用的 Skill。不要重复已经被其他工件(PRD、计划、ADR、Issue、commit、diff)记录的内容,改为通过路径或 URL 引用。脱敏任何敏感信息,如 API key、密码或个人身份信息。如果用户传入了参数,将它们视为对下一个会话重点的描述,按此来定制文档。)
这六句话背后有五个精细的设计决策:
(1)"不要重复已回答的问题。" 这是交接文档最常见的失败模式——把 PRD、ADR、Issue、commit diff 的内容重新抄写一遍。应该引用路径,而不是复制内容。一份好的 handoff 只包含"除了已有工件之外还需要知道的东西"——当前卡在哪里、为什么选择了 A 而不是 B、还有哪个假设尚未验证。
(2)"建议下一步要用的 Skill。" 交接不只是传递信息,也是传递工作状态的上下文。如果上一个 Agent 在 /grill-with-docs 中完成了对齐但还没写 PRD,交接文档应该明确指出"下一步运行 /to-prd"。这让"交接"不再是"把东西放在那里等人来找",而是"主动传递下一步行动指引"。
(3)"保存到操作系统临时目录,不是工作区。" 这是一个工程直觉:工作区不应当是垃圾场。交接文档是瞬态的——它将被下一个会话消费后删除。它存放在 $TMPDIR 或 /tmp 中,生命周期和它服务的任务一样短。
(4)"自动脱敏。" 这是 Pocock 的安全直觉:交接文档中不准出现 API key、密码、个人身份信息。虽然 Agent 不会把这些发到外部,但交接文档以明文存储在磁盘上——它不应该成为一个意外的秘密泄露点。
(5)"按用户描述的下一个会话目标来定制。" 如果用户运行 /handoff "继续做 setup 页面",交接文档应该侧重 setup 页面的当前状态和待解决的设计问题,而不是重复整个项目的 PRD。
这五个决策共同建立的是一种"半衰期"意识:一个会话可以持续很长时间,但它不能永远存在。Agent 的上下文窗口有边界、API 会话有时间限制、人类的专注力也有极限。/handoff 承认了这个物理现实,并提供了一个工程化的应对方案:在边界处把状态压缩为一份上下文高效的文档,让下一个会话可以冷启动。
它是 Pocock 的 Skills 体系在与项目交接和工作连续性方面的延伸——它回答了"当 AI 工程会话本身需要考虑工程化时,我们如何设计会话的接口"。这需要交接和状态传递,交接和状态传递需要结构化——这是工程实践的本质。
2.7 全量 Skill 一览
以下是 mattpocock/skills 仓库 Skill 的总览表(据仓库 main 分支,截至 2026 年 7 月)。分类沿用 Pocock 自己的目录结构(skills/ 下按 engineering/、productivity/、misc/、personal/、in-progress/、deprecated/ 分桶)。
Engineering Skills(工程类)——日常编码工作中使用的核心技能。Pocock 在 README 里把它们又按调用方式分成两轴:User-invoked(只有你敲斜杠才触发,负责编排)和 Model-invoked(你能敲,Agent 判断任务合适时也会自动拉起,装的是可复用的纪律):
| Skill | 调用 | 一句话描述 |
|---|---|---|
/ask-matt |
User | 一个路由器——你说不清该用哪个 skill 时,它帮你选对入口和流程 |
/grill-with-docs |
User | 盘问每个决策分支,同步搭领域模型、更新 CONTEXT.md 和 ADR |
/triage |
User | 按状态机模型对 Issue(及外部 PR)分类、打标签 |
/improve-codebase-architecture |
User | 扫描代码库找"深度模块"机会,出可视化 HTML 报告,再逐个盘问 |
/setup-matt-pocock-skills |
User | 配置 Issue 追踪器、Triage 标签、文档路径;其他工程 Skill 的前置步骤 |
/to-tickets |
User | 把 plan/spec/对话拆成一串曳光弹 ticket,每个声明自己的阻塞边,可写成本地文件或追踪器原生阻塞链接 |
/to-spec |
User | 把当前对话合成为规格(spec)并发布到 Issue 追踪器,不再追问 |
/implement |
User | 照着 spec 或一组 tickets 把活干出来,在约定接缝处驱动 /tdd,收尾跑 /code-review 再提交 |
/wayfinder |
User | 为超出单次会话容量的大块工作探路:在 Issue 追踪器上画一张调研 ticket 地图(fog of war 式),逐个解决直到通往目的地的路线清晰(v1.1 从 in-progress/ 毕业,前身 decision-mapping) |
/diagnosing-bugs |
Model | 六阶段调试循环:建反馈回路→复现→假设→插桩→修复→回归(原 /diagnose) |
/tdd |
Model | 红-绿循环(重构已移至 /code-review),只在约定接缝处测试,垂直切片,禁止水平切片 |
/prototype |
Model | 搭抛弃型原型回答设计问题——可跑的终端应用或多套可切换的 UI 变体 |
/research |
Model | 带着问题查一手来源,把发现落成带引用的 Markdown 文件,作为后台 agent 跑 |
/code-review |
Model | 双轴审查 diff:Standards(编码规范 + Fowler 坏味道基线)+ Spec(是否忠实实现原始 issue/PRD),并行子 Agent 执行 |
/codebase-design |
Model | "深度模块"的共享词汇与纪律:把大量行为收进一个小接口、放在干净的接缝上 |
/domain-modeling |
Model | 主动搭建并打磨项目领域模型,用边界场景压测术语,同步更新 CONTEXT.md 和 ADR |
/resolving-merge-conflicts |
Model | 处理进行中的 git merge/rebase 冲突的循环,独立无依赖 |
Productivity Skills(生产力类)——通用工作流工具,不限于编码:
| Skill | 调用 | 一句话描述 |
|---|---|---|
/grill-me |
User | 穷举式盘问一个计划或设计,直到决策树每个分支都闭合,但不写文档 |
/handoff |
User | 将当前对话压缩为交接文档,供下一会话冷启动 |
/teach |
User | 把当前目录当有状态的教学工作区,跨多次会话教你一门技能或概念(详见第 36 章) |
/writing-great-skills |
User | 写和改 Skill 的参考:让 skill 可预测的词汇与原则(v1.1 起取代 /write-a-skill) |
/grilling |
Model | grill-me 和 grill-with-docs 背后那段可复用的盘问循环,被抽出来单独暴露 |
Misc Skills(杂项)——特定场景的一次性工具:
| Skill | 功能 | 一句话描述 |
|---|---|---|
/git-guardrails-claude-code |
Git 安全护栏 | 为 Claude Code 设置 hooks,拦截危险的 git 命令 |
/migrate-to-shoehorn |
测试迁移 | 将 as 类型断言迁移为 @total-typescript/shoehorn |
/scaffold-exercises |
练习脚手架 | 创建带章节、问题、解答和讲解的练习目录结构 |
/setup-pre-commit |
预提交钩子 | 安装 Husky + lint-staged + Prettier + 类型检查 + 测试 |
Personal Skills(个人类)——Pocock 自己使用的非通用技能,仅供参考:
| Skill | 功能 | 一句话描述 |
|---|---|---|
/edit-article |
文章编辑 | 重构章节、提升清晰度、收紧文字 |
/obsidian-vault |
Obsidian 笔记 | 在 Obsidian vault 中搜索、创建、管理笔记 |
开发中(In-Progress)——放在 in-progress/ 目录,尚未正式发布,功能可能变更:
| Skill | 功能 | 一句话描述 |
|---|---|---|
/loop-me |
工作流规格盘问 | 在工作区里跑有状态的 /grilling,唯一产物是工作流的规格 |
/claude-handoff |
交接给后台 agent | 像 /handoff 但不落盘,直接起一个后台 claude --bg agent 接着干 |
/wizard |
生成交互式向导 | 生成一个 bash 向导,带人走完手动流程(第三方配置、一次性迁移、写 .env 和 GitHub secrets) |
/writing-beats |
节拍式叙事写作 | 每次只写一个"节拍",写完提供下一方向选项,逐段推进 |
/writing-fragments |
写作碎片收集 | 盘问式挖掘用户的论点、金句、半成形想法,汇总为未来文章的素材库 |
/writing-shape |
文章塑形打磨 | 将一堆原始素材通过对话打磨成可发表文章,逐段推敲格式和结构 |
后三个写作 Skill 构成 Pocock 为自己设计的写作工作流三阶段:碎片收集 → 节拍叙事 → 文章塑形。
已废弃(Deprecated)——已被其他 Skill 取代或不再维护:
| Skill | 功能 | 被替代原因 |
|---|---|---|
design-an-interface |
接口设计探索 | 功能并入 /prototype |
qa |
对话式 QA 会话 | 功能并入 /triage 和 /to-tickets(/to-issues 已改名 /to-tickets) |
request-refactor-plan |
重构计划 | 功能并入 /improve-codebase-architecture |
ubiquitous-language |
统一语言提取 | 功能并入 /grill-with-docs 的 CONTEXT.md 更新机制 |
此表中的 Engineering Skills 构成了 Pocock 体系的核心——覆盖了意图对齐、需求结构化、测试驱动实现、系统化调试、代码审查、架构审计的完整闭环。Productivity Skills 解决的是"人类与 Agent 的通信效率"——压缩、对齐、交接、创造。两类 Skills 互为补充:Engineering 决定产出质量,Productivity 决定协作效率。
2.7.1 仓库还在长
这个仓库是 Pocock 每天在用、持续打磨的东西,roster 一直在变。写作时对照 main 分支,几处变动正好说明这套体系怎么迭代:
- 分类换了一根轴。原来分 Commands / Skills,现在改成 User-invoked / Model-invoked,并加了
docs/invocation.md讲清规则:user-invoked 只有你敲斜杠才触发、负责编排;model-invoked 你能敲、Agent 也能在任务合适时自动拉起,装的是可复用的纪律。一条硬约束——user-invoked 可以调 model-invoked,但绝不调另一个 user-invoked。 - 抽出了两个共享的"设计"Skill。
/codebase-design(深度模块的词汇与原则,原来埋在improve-codebase-architecture/LANGUAGE.md里,现在提出来通用化)和/domain-modeling(主动搭建、压测领域模型)。/improve-codebase-architecture、/tdd、/grill-with-docs都改成依赖这两个新 skill,而不再各自内联一份。这是"小而可组合"原则自己作用到自己身上:把重复的纪律抽成底座。 /grilling被单独暴露。/grill-me和/grill-with-docs背后本来就是同一段盘问循环,现在把它抽成一个 model-invoked 的/grilling供复用。- 加了个路由器
/ask-matt。你说不清该用哪个 skill 时,它帮你选入口——skill 多到需要一个 skill 来导航,本身就说明了体系的规模。 /implement、/resolving-merge-conflicts补齐了缺口。/implement照着 PRD 或一组 Issue 直接干活;/resolving-merge-conflicts处理进行中的 git merge/rebase 冲突,独立无依赖。/research的加入和/code-review的毕业见下方 v1.1 一节。- 删繁与改名。
/caveman和/zoom-out被移除(前者是误放进来的测试品,后者实际没人用);/diagnose改名/diagnosing-bugs;/write-a-skill被/writing-great-skills取代。2.5、2.6 走查沿用的旧名见本节末尾的时间差说明。 /teach改成"复用优先"。每课不再各写各的,而是先读./assets/里已有的组件(样式表、测验控件、图表助手),能复用就复用,新做的东西也抽成组件。第 36 章的 zero-learn 工作区正是这套复用逻辑的活样本。
v1.1(2026-07-08 发布):从"路线预告"到正式落地。 上一版写作时,Pocock 在 X 上预告的 /to-spec、/to-tickets、/wayfinder 还没落到 main 分支;v1.1.0 发布后这些全部落地,体系又往前迈了一步:
/wayfinder从in-progress/毕业到engineering/(User-invoked)。前身叫decision-mapping,名字拗口且不准确(只有一种 ticket 真的是"决策")。改名wayfinder后用一套连贯的"战争之雾(fog of war)/ 前线(frontier)/ 地图(the map)"框架统一了语境:先命名"目的地"(## Destination),地图只产决策不产交付物,是索引不是仓库(一条决策只活在它自己的 ticket 里)。地图从本地 Markdown 搬到 Issue 追踪器上(一条wayfinder:mapissue,子 issue 即 ticket),靠 native blocking 关系把"哪些现在能领"可视化;领取靠指派、不靠标签;新增第四种taskticket(唯一"做事"而非"决策"的类型);每张 ticket 标 HITL(要人在回路)或 AFK(agent 独立跑),这修掉了早期学生反馈的"/wayfinder自己盘问自己"的问题。Pocock 特意把它定位成"情境入口"而非新的主干流程:以 grill 起步的 idea 到 ship 链条仍是正门,把 wayfinder 加冕为默认脊柱是 v2 才会做的事。/to-prd改名/to-spec,/to-plan+/to-issues合并成/to-tickets。"spec" 成了贯穿全文的唯一术语(开头仍写一句"你可能更熟悉 PRD 这个叫法"便于检索)。/to-tickets把 plan/spec/对话拆成一串曳光弹式的 ticket,每张声明自己的阻塞边,这一份产物按setup-matt-pocock-skills配的追踪器读出两种形态:本地文件(tickets.md,边写成文本,从上往下手动推进)或真实追踪器(边写成原生阻塞链接,任何前置完成的 ticket 自动上前线,多个 agent 可并行)。它还学会处理"宽重构"(wide refactor):一次波及全代码库的机械改动(如改列名)爆炸半径太大,没有任何垂直切片能单独跑绿,于是改成 expand-contract(新旧并存、按爆炸半径分批迁移、最后收掉旧形态)分批推进,让 CI 逐批保持绿色。/implement+/code-review闭合了整个生命周期。/implement照着 spec 或一组 tickets 干活,在预先约定的"接缝"处驱动/tdd,收尾时跑/code-review再提交。/code-review本身也在 v1.1 从in-progress/(当时叫/review)毕业到engineering/,正式随插件发布,双轴并行(Standards + Spec),并在 Standards 轴上常驻一份 Fowler 坏味道基线(约 12 条:神秘命名、重复代码、特性依恋、数据泥团、基本类型偏执、重复 switch、霰弹式修改、发散式变化、投机性泛型、消息链、中间人、拒绝继承)。两条约束保安全:仓库自有规范优先于基线,且每条坏味道都作为判断而非硬违规上报。/research与/prototype补上"动手前先把事实和形态搞准"。/research是 v1.1 新增的 Model-invoked skill:起一个后台 agent 对照一手来源(官方文档、源码、规范、第一方 API)查问题,把结论落成一份带引用的 Markdown 文件留在仓库里——你继续干活,它替你读,读完还你一份可以拿去 grill/plan/design 的文档。/prototype在 v1.1 改成 Model-invoked,让 agent 能自主够到它(别的 skill 也能):抛掉式原型回答一个设计问题,状态/逻辑疑问就搭个能跑的终端应用,UI 疑问就做多套可从一个路由切换的截然不同的界面变体。两者既能独立用,也专门支撑/wayfinder的探路。/tdd瘦身成 reference-only。红-绿-重构里的"重构"被拿掉,挪到/code-review(TDD 现在是红-绿);逐循环 checklist 和 Workflow 段落删除(红绿循环靠模型已有的 leading word 锚定,步骤多是复述),只留下"垂直切片/曳光弹"反模式和简短的循环规则;引入 seam(接缝) 作为"测试该写在哪"的 leading word,只在预先约定、且写测试前和用户确认过的接缝处测。还补了"同义反复测试"反模式(断言用和实现同样的算法重算一遍,构造上必过、零信心)。/grilling加了确认闸门,并区分"事实"与"决策"。agent 不会在达成共识前就动手执行计划,把"达成共识"这条完成标准变成了显式停止闸;同时把要查的事(去代码库里查)和要人定的事(每条单独抛给人、等回答)分开。旧版的"能查代码就查代码"是给"人在回路"写的,但被别的 skill 在"解决 ticket"框架里调用时,会被读成"决策也能自己答"的许可,导致盘问 agent 抢跑。/ask-matt路由器补齐全套。v1.1 把它对齐了当时漏掉的 skill:补上/tdd(作为/implement驱动的红绿引擎织进主干)、/diagnosing-bugs(新增"出 bug 了"入口,此前没有 bug 的路由)、/domain-modeling+/codebase-design(新增"底层词汇"段)和/grilling;/prototype作为独立项 fleshed out。CLAUDE.md 还加了一条维护规则:今后任何 skill 增删改名或流程变动都触发 ask-matt 复查。- 其它。
/triage扩展到能分诊外部 PR(把 PR 当成带代码的 issue 走同一套角色状态机);/writing-great-skills加了两个"语言即转向"失败模式:Negation(大象)(用禁止来转向,反而把被禁行为拉进上下文,治法是写正向)和 Negative Space(留白)(你省掉的每个决策都默认委托给了模型先验,治法是逐条审视沉默处)。
表格是 v1.1.0(2026-07-08)发布后某一时刻的快照,仓库本身一直在动。需要提醒一处时间差:2.5、2.6 的走查是更早一次实跑的记录,沿用了当时的命令名——/to-prd、/to-issues 现在分别是 /to-spec、/to-tickets,/diagnose 现在是 /diagnosing-bugs,而 /zoom-out 已在 v1.0 被移除(它"给系统画张地图"的活现在更多落到 /codebase-design 和 /domain-modeling 上)。走查的逻辑不变,叫法以本节表格为准。
2.8 本章小结
Matt Pocock 的 Skills 系统是 AI 时代软件工程方法论图谱中的基石项目。它的贡献不在数量——这方面后续的 superpowers 和 gstack 远在其上——而在回答了最重要的问题:
一个可复用的 AI 工程能力单元应该如何设计?
它的回答是四个原则:小而可组合——一个 Skill 只做一件事;描述即行为——Skill 的唯一可执行逻辑是 Markdown 中的自然语言指令;模型无关——不绑定任何特定模型或平台;可改造——用户始终保留修改任何 Skill 的全部权利。
这四个原则代表了一个价值判断:工程师保留对流程的全部控制权。 工具只提供服务,流程应始终在工程师手中。
在这个哲学之下,Skills 系统通过四种方式解决四种失败模式:/grill-me + 共享语言(CONTEXT.md)解决"意图不一致"和"AI 过于啰嗦";/tdd + /diagnosing-bugs 解决"代码跑不起来";/codebase-design、/domain-modeling + /improve-codebase-architecture 解决"一团浆糊"。这些 Skill 不是各自独立的散件,它们串起来覆盖了"意图→通信→实现→设计"的全过程。
这个体系为全书奠定了基础:
- 第 3 章的 Spec-Driven Development 在 Skills 的基础上扩展为更完整的规格管理——"先定合约再写代码";
- 第 5 章的 gstack 将 Skills 思维贯彻为 23 个专业角色——"一人成军"的虚拟工程团队;
- 第 6 章的 superpowers 用 159K+ Stars 证明了 Skills 可以是社区级的基础设施;
- 第 10 章的 Harness Engineering 则进一步讨论了为 AI Agent 提供运行环境需要的结构化基础设施——hooks、权限模型、配置管理——是 Skills 系统在平台层面的工程支撑。
但所有这些更复杂的体系,其起点都是一个简单的想法:回到一个 Markdown 文件的纯粹。「做一个功能」不如「写一个 Skill」;「跑一条流水线」不如「积累知识」;「用 AI 替代我的判断」不如「用 AI 放大我的判断」。
Pocock 在 README 结尾处写道:"Software engineering fundamentals matter more than ever." 软件工程的基本原则比以往任何时候都更重要。这正是全书中继续的旋律——从第 2 章到第 18 章,用一套完整的案例来证明。
下一章将展开 Skills 思维的第一种大规模应用:Spec-Driven Development——当 Skill 不再只是"一个能力单元",而是"你的项目规格"和"测试和代码之间的合约"。
留言板
欢迎在此分享你的想法!评论通过 GitHub Issues 存储,需要 GitHub 账号登录。