第6章: superpowers 技能框架 —— Agent 能力增强
"The agent checks for relevant skills before any task. Mandatory workflows, not suggestions."
Agent 在执行任何任务之前,先检查自己有没有对应的技能。这些是强制工作流,不是建议。
——Jesse Vincent, Superpowers 作者, 2025 年
gstack 用二十三个角色和七个 Sprint 阶段构建流程驱动的虚拟工程团队。CEO 审方向,工程经理锁架构,QA 测功能,安全官审漏洞——每个角色在固定阶段做固定的事。
superpowers 走相反的路。
superpowers 不定义任何角色。不强制任何 Sprint 阶段。它只做一件事:给你十四个 Skill,让 Agent 自己在合适的时机调用合适的那个。不靠流程锁住质量——靠每个 Skill 足够好用,Agent 自己愿意用它们。
201K+ Stars。当你不信任流程、只信任工具时,AI 软件工程能做多大——这个数字就是答案。
6.1 一个拒绝流程的系统
superpowers 的作者是 Jesse Vincent,Prime Radiant 的创始人。他给这个项目起的名字——"超能力"。让一个普通 AI Agent 变成一个有方法论的 Agent 的十四种超能力。

2025 年 10 月发布,不到一年冲到 201K+ Stars。这个数字在所有 AI 编程方法论相关仓库里排第一——超过 gstack(约 5K),超过 OpenSpec(约 49K),超过 Ralph Loop 所有实现的总和。
从 README 第一段就能看出来:
"It starts from the moment you fire up your coding agent. As soon as it sees that you're building something, it *doesn't* just jump into trying to write code. Instead, it steps back and asks you what you're really trying to do."
Agent 启动时不写代码。它退一步,先问你想做什么。这个行为是 Skill 自动触发的——Agent 检测到自己即将开始开发工作时,brainstorming 技能自动激活,强制走一轮需求澄清。
gstack 的流程是人类驱动的——你手动调用 /office-hours,然后 /plan-ceo-review,然后 /autoplan。superpowers 的流程是 Agent 驱动的——你只需要打开 Agent 开始工作,它在合适的时机自动加载合适的 Skill。你不说"先做设计",Agent 自己知道要先做设计。
两条路。gstack 要的是控制——流程固定,角色明确,每个阶段的输出和输入都有明确的合约。superpowers 要的是自主——给 Agent 十四种能力,让它自己判断什么时候该用什么。
6.2 核心机制:自动触发 + 强制门控
superpowers 的十四个 Skill 并不新。brainstorming、TDD、systematic-debugging——这些概念第二章的 Pocock Skills 里都有。superpowers 的不同在两个地方。
6.2.1 自动触发:Agent 自己决定用什么 Skill
Pocock 的系统里,用户手动调用 /tdd、/diagnose、/grill-me。gstack 里,用户手动走 Sprint 阶段。
superpowers 的设计是:每个 Skill 的 description 字段里写了触发条件。Agent 在执行任务前检查所有已加载 Skill 的 description,匹配当前场景就自动激活。比如 Agent 准备写代码时,brainstorming 的 description 是"你必须在任何创造性工作之前使用此技能",Agent 读到这句话,强制自己先做需求澄清。
一个文本匹配机制,Agent 会跳过吗?效果出奇地好。关键在 description 的措辞。它不说"建议使用此技能",说"在任何创造性工作之前必须使用此技能"。不说"可以考虑 TDD",说"强制执行红-绿-重构:先写会失败的测试,看着它失败,写最少代码让它通过,看着它通过,提交。删除在测试之前写的任何代码。"命令式的、不可协商的语言,Agent 就会遵守。
6.2.2 硬门控:HARD-GATE 标签
有些 Skill 里嵌了一段特殊代码:
<HARD-GATE>
Do NOT invoke any implementation skill, write any code, scaffold any project,
or take any implementation action until you have presented a design and the
user has approved it.
</HARD-GATE>HARD-GATE 是给 Agent 的行为约束——在进入下一个阶段之前,必须先完成当前阶段的硬性条件。brainstorming 有它——设计没被批准,一行代码都不准写。test-driven-development 有它——测试没写、没看到它失败,不准写实现代码。
gstack 用 PreToolUse hooks 在系统层面锁住 commit 按钮。superpowers 用 prompt 内嵌的指令在 Agent 认知层面锁住行动。前者是操作系统的强制,后者是心理的强制。都有效,但原理不同。hooks 在你的平台不支持时就失效了。HARD-GATE 在任何平台上都有效——它只是 prompt 里的一段文本。但它也更软——依赖 Agent 遵循指令的能力。在 Claude 4.x 上表现良好,在更弱的模型上可能被跳过。
6.3 十四种超能力
superpowers 把十四个 Skill 分成了五组。
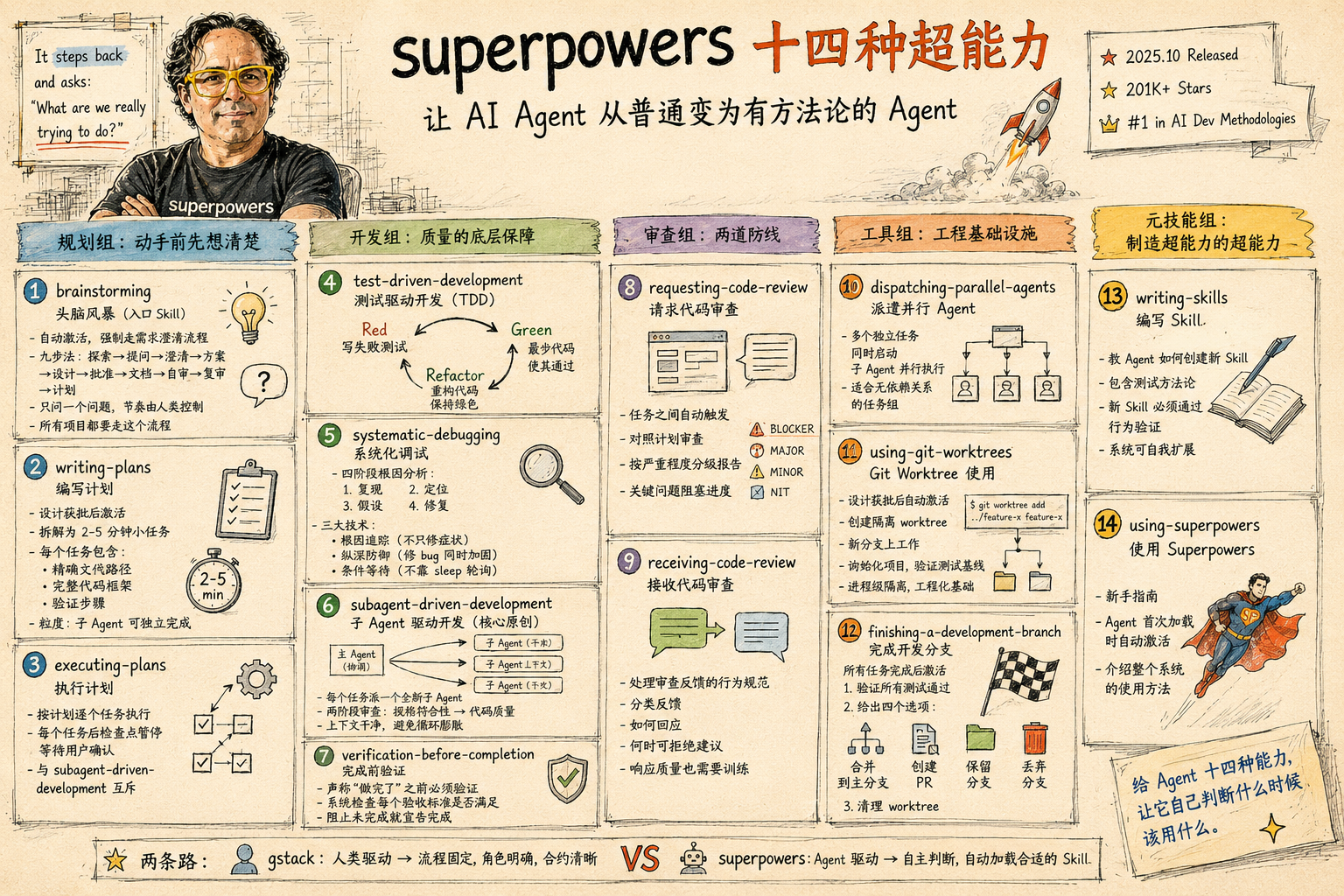
6.3.1 规划组:动手前先想清楚
brainstorming(头脑风暴)。这是整个系统的入口 Skill。Agent 检测到开发任务时自动激活,执行九步流程:探索项目上下文 → 询问视觉需求 → 逐个澄清问题 → 提出 2-3 个方案并推荐 → 分段展示设计 → 用户批准 → 写入设计文档 → 自审 → 用户复审 → 进入实施计划阶段。
它强制 Agent "一次只问一个问题"(Only one question per message)。这个约束防止了 Agent 一次性抛出十几个问题让用户不知所措——AI 常见的"过度热情"在这种设计下被抑制了。每一步都要等用户回答,节奏是人类控制的。
Skill 的态度很明确:每个项目都要走这个流程。todo list、一个函数、一个配置修改——全部要。简单的项目设计可以很短(几句话),但必须被呈现和批准。
writing-plans(编写计划)。设计被批准后激活。把设计方案拆成 2-5 分钟能完成的小任务。每个任务包含精确的文件路径、完整的代码框架、验证步骤。粒度设计有一个清晰的标准:一个任务必须小到可以被一个子 Agent 在隔离的上下文中独立完成。
executing-plans(执行计划)。按计划逐个任务执行,每个任务完成后检查点暂停等待用户确认。和下面的 subagent-driven-development 是互斥的两条路径——前者适合需要人在循环中的场景,后者适合自主执行的场景。
6.3.2 开发组:质量的底层保障
test-driven-development(测试驱动开发)。红-绿-重构的严格执行——先写会失败的测试,看着它失败,写最少代码让它通过,看着它通过,提交。最狠的规则:删除在测试之前写的任何代码。断了"先写实现再补测试"这条路。
红-绿-重构是 TDD 的核心循环。红——先写一个会失败的测试,确认测试确实失败了(不是假通过)。绿——写最少量的代码让测试通过,不求优雅,只求过关。重构——测试全绿后,清理代码结构,消除重复,改善命名,测试必须保持绿色。然后下一个循环。三步顺序不能乱:先有失败的测试,才有资格写实现代码。
systematic-debugging(系统化调试)。四阶段根因分析:复现 → 定位 → 假设 → 修复。包含三个子技术:根因追踪(不只修症状)、纵深防御(修 bug 同时加固相关路径)、条件等待(不靠 sleep 轮询)。
subagent-driven-development(子 Agent 驱动开发)。这是 superpowers 最具原创性的 Skill。核心逻辑:每个任务派一个全新的子 Agent 去实现,主 Agent 只负责协调。每个任务完成后两阶段审查:先审规格符合性(代码是不是做了该做的事),再审代码质量(代码写得好不好)。子 Agent 上下文是干净的——主 Agent 精确构造子 Agent 需要的上下文,不把整个会话历史塞进去。主 Agent 自己的上下文窗口留给协调工作。
这直接回应了第 4 章 Ralph Loop 的一个已知问题:循环膨胀。一个 Agent 在同一个会话中连续迭代十几次,上下文中的噪音(失败的尝试、被废弃的思路、旧的代码片段)越积越多,决策质量逐渐下降。子 Agent 模式通过"每个任务一个新 Agent"解决了这个问题——每个子 Agent 的上下文都是干净的,只包含完成当前任务所需的最小信息。
verification-before-completion(完成前验证)。声称"做完了"之前必须跑验证——系统地检查每个验收标准是否被满足,不满足于"测试跑过一次通过了"。这和 Ralph Loop 的 completion promise 做的事一样:阻止 Agent 在没做完的时候说自己做完了。
6.3.3 审查组:两道防线
requesting-code-review(请求代码审查)。任务之间自动触发。对照计划审查,按严重程度分级报告问题。关键问题阻塞进度。
receiving-code-review(接收代码审查)。处理审查反馈的行为规范——如何分类反馈、如何回应、什么情况下可以拒绝修改建议。Agent 响应审查反馈的方式和质量也需要训练。
6.3.4 工具组:工程基础设施
dispatching-parallel-agents(派遣并行 Agent)。多个独立任务同时启动子 Agent 并行执行。适合计划中有明显无依赖关系的任务组。
using-git-worktrees(Git Worktree 使用)。设计被批准后自动激活——创建隔离的 git worktree,在新分支上工作,跑项目初始化,验证测试基线。和第 10 章的 Harness Engineering 一脉相承——用 git worktree 实现进程级隔离,而不是依赖 Agent 的自我约束。
finishing-a-development-branch(完成开发分支)。所有任务完成后激活。验证所有测试通过,给出四个选项:合并到主分支、创建 PR、保留分支、丢弃分支。清理 worktree。
6.3.5 元技能组:制造超能力的超能力
writing-skills(编写 Skill)。教 Agent 怎么样创建一个新 Skill。包含测试方法论——新 Skill 写完后必须通过行为验证。有了 writing-skills,superpowers 就成了一个可以自我扩展的系统。
using-superpowers(使用 Superpowers)。介绍整个系统的新手指南。Agent 第一次加载 superpowers 时自动激活。
6.4 superpowers-zh:中文生态的本地化
superpowers-zh 由 jnMetaCode 开发,3.6K+ Stars。完整汉化,加六个中国原创 Skill。
六个原创 Skill 瞄准的是中文开发者自己的场景:
chinese-code-review 适配了国内团队的代码审查文化——审查报告的措辞、评论的优先级标注、修改建议的表达方式,都按国内工程师习惯的交流方式重新设计,不是简单翻译英文版。chinese-git-workflow 支持 Gitee、CODING、极狐 GitLab、CNB 等国内代码托管平台——git worktree 的创建、PR/MR 的提交和合并流程都做了适配。chinese-documentation 强制中文排版规范——中英文之间的空格、标点符号的使用、技术术语的翻译标准。chinese-commit-conventions 将 Conventional Commits 规范适配到中文团队的实践——中英混合的 commit message 格式、中文 Issue 引用格式。mcp-builder 直接教 Agent 如何构建 MCP 服务器。workflow-runner 提供了多角色的 YAML 编排能力——弥补了 superpowers 原生不支持流程编排的短板。
目前支持十六款 AI 编码工具,从 Claude Code 到通义灵码(Qwen Code),一键安装自动检测平台。superpowers-zh 进一步扩大了跨平台兼容性——原版不支持的中国本土工具也被加了进来。
6.5 实战:用 superpowers 开发网页版贪吃蛇
同一个贪吃蛇。第五种体验。
6.5.1 启动:Agent 拒绝写代码
打开 Claude Code(已安装 superpowers),输入:
做一个贪吃蛇网页游戏。纯前端单文件。在 Pocock Skills 下,Agent 可能直接开始写代码。在 gstack 下,你会手动调用 /office-hours。在 superpowers 下,Agent 的行为是自动的——brainstorming 技能检测到"creating features, building components"的场景,自动激活:
Agent: 在我开始之前,我需要先了解一些关键问题。你是想做一个完整的游戏,还是更偏向一个技术演示?(一次只问一个问题)
用户:演示项目。展示 AI 编码能力。
Agent: 了解了。演示项目意味着代码需要干净、可读、可展示。那么核心体验上——你希望这个游戏"看起来不错"更重要,还是"代码结构清晰"更重要?
用户:代码清晰更重要。
Agent: 明白了。那验收标准上——哪些行为是必须的,哪些是可以省略的?
用户:蛇能动,能吃食物,撞墙或撞到自己会死,死了能重来。最高分用 localStorage 存。
Agent: 好的。让我确认几个技术偏好:纯单文件 HTML/CSS/JS,不依赖任何框架?
五个问题后,Agent 产出一份设计文档,存入 docs/superpowers/specs/。然后自动过渡到 writing-plans——把设计拆成四个任务:
- HTML 结构与 Canvas 渲染(20x20 网格,初始蛇 3 格,红色食物)
- 游戏循环与状态管理(requestAnimationFrame,150ms/步,nextDirection 缓冲防反向)
- 碰撞检测与食物系统(墙壁、自身、食物随机生成且不与蛇身重叠)
- 分数系统与 UI 状态(当前分/最高分、HTML modal 弹窗、localStorage、空格键重置)
每个任务标注了文件路径、实现要点、验证步骤。然后 Agent 开始执行。
6.5.2 子 Agent 驱动的实现过程
subagent-driven-development 激活。主 Agent 为每个任务派一个全新的子 Agent:
任务 1——派子 Agent A,只给 HTML 结构和 Canvas 渲染的上下文。子 Agent 在干净的环境中写代码,跑验证,提交。主 Agent 派审查子 Agent 做两阶段审查(规格符合性 → 代码质量),通过。
任务 2——派子 Agent B,只给任务 2 的上下文加上已完成的文件结构。子 Agent 实现了游戏循环和方向控制。审查子 Agent 发现了一个问题:方向缓冲的默认值没初始化,蛇可能在按键前就开始移动。打回修改。子 Agent B 修好,重新审查,通过。
任务 3——派子 Agent C,加碰撞检测和食物系统。审查通过。
任务 4——派子 Agent D,加分数系统和 modal 弹窗。审查子 Agent 提出:modal 弹窗出现时键盘事件没拦截,死了还能控制蛇。这是第 5 章 gstack 实战中 Review 阶段才发现的问题——在 superpowers 的流程里,子 Agent 审查阶段就揪出来了。子 Agent D 修复,重新审查,通过。
整个过程约十五分钟,人类参与了两次——回答 brainstorming 的五个问题,确认设计方案。其余全自动。
6.5.3 验证和交付
verification-before-completion 激活。Agent 逐条对照验收标准验证:蛇能动 ✓ 能吃食物 ✓ 撞墙死 ✓ 撞自己死 ✓ 分数更新 ✓ 最高分持久化 ✓ 空格键重置 ✓。全部通过后 Agent 报告完成。
finishing-a-development-branch 激活。Agent 给出四个选项,用户选择创建 PR。Agent 生成 commit(Conventional Commits 格式),推送到远程,创建 PR。
6.5.4 superpowers 和其他方法论的对比
同一个贪吃蛇,五种方法论:
| 维度 | Pocock Skills | OpenSpec | Ralph Loop | gstack | superpowers |
|---|---|---|---|---|---|
| 启动方式 | 手动调用 Skill | 手动写 proposal | 手动写 prompt | 手动运行 /office-hours |
Agent 自动激活 brainstorming |
| 人类参与度 | 全程驾驶 | 每步写文档 | 写 prompt 后放手 | 逐个阶段运行命令 | 回答设计问题后放手 |
| Agent 自主性 | 低 | 中 | 高 | 中 | 高 |
| 审查机制 | Skill 内建验证 | Spec 验收标准 | 自动重试+测试 | 四个角色分维度审查 | 子 Agent 两阶段审查(规格+质量) |
| 上下文管理 | 单 Agent 累积 | 单 Agent 累积 | 单 Agent 累积 | 多角色但同一会话 | 每个任务新子 Agent,上下文隔离 |
| 流程强制力 | 引导 | 柔性门 | 自动循环 | 系统 hooks | 认知门控(HARD-GATE) |
| 最佳场景 | 日常小任务 | 有规格的功能 | 可自动验证的任务 | 从零到一的完整项目 | 中等复杂度的独立功能 |
superpowers 在贪吃蛇上只花了约十五分钟——比 gstack 的七个阶段快,比 Ralph Loop 的四轮迭代质量高(子 Agent 审查抓到了 Ralph 第 4 轮才抓到的 modal 焦点问题)。人类的参与时间约五分钟。
superpowers 没有 gstack 那种"CEO 审方向 → 工程经理锁架构 → 设计师审 UI"的全景角色覆盖。它依赖十四种工具覆盖足够多的场景——如果某个场景没有对应的 Skill,Agent 就没有那个维度的审查能力。gstack 的二十三个角色覆盖了产品、工程、设计、安全、运维的全部维度。superpowers 的十四个 Skill 更多地集中在工程实现环节,产品思考和安全管理相对薄弱。
6.6 设计哲学:自动化的代价
superpowers 和 gstack 是两条路。核心差异不在 Skill 数量——14 vs 35+。在谁驱动流程。
gstack 是人驱动流程。你判断什么时候进入 Think 阶段,你调用 /office-hours。你判断什么时候进入 Plan 阶段,你调用 /autoplan。流程的节奏和方向在你手上。好处是你能在每一步做出判断——CEO 审查结论否决了难度曲线功能,你知道为什么,你同意这个决定。坏处是你必须在每一步都参与——七个 Sprint 阶段走一遍,意味着你要在电脑前坐几个小时。
superpowers 是Agent 驱动流程。Agent 判断自己即将开始开发,自动激活 brainstorming。Agent 判断自己需要写实现计划,自动激活 writing-plans。流程是 Agent 自己推进的。好处是你只需要在关键决策点参与——设计批准时看一眼,方案选择时给个意见——剩下的 Agent 自己跑。坏处是 Agent 可能在你不注意的时候做出你不同意的决策。
两套系统对"信任"的假设相反。gstack 的假设是:你不能信任 AI 的自我判断——它会在应该先做设计时直接写代码,会在没做完时声称做完了。所以用系统级别的门控来强制执行。superpowers 的假设是:你可以部分信任 AI——给它好用的工具和清晰的行为约束(HARD-GATE),它会在大多数时候做出正确的选择。
哪种假设更接近现实?取决于你用的模型和任务的复杂度。Claude 4.x 上 superpowers 的自动触发表现良好——Agent 确实会在应该先做设计时停下来问问题。但在更弱的模型上,HARD-GATE 只是一段文本,Agent 可能直接跳过。gstack 的 hooks 门控在任何模型上都有效,但只在支持 hooks 的平台上有效。
Jesse Vincent 对这个问题的回答很务实:superpowers 不支持弱模型。项目明确要求 Claude 4.x 或同等能力的模型。如果你用的是弱模型,superpowers 不提供保障——它假设 Agent 有基本的指令遵循能力。
6.7 适用边界
superpowers 不像 gstack 那样有明确的"绿野项目""治理轨迹""单人团队"三类最佳场景。它的适用逻辑更简单——看任务类型。

最适合:
- 中等复杂度的功能开发。 一个独立的 CRUD 模块、一个 UI 组件的重构、一个数据处理的管道——任务足够复杂,值得走 brainstorming → plan → subagent 实现的完整流程;任务又足够独立,不需要跨系统的架构决策。这是 superpowers 的最佳区间。
- 需要长时间自主执行的场景。 subagent-driven-development 的核心优势是上下文隔离——每个子 Agent 带着最少的、最精确的上下文开始工作,不会被前面十几个任务的噪音干扰。这让 Agent 可以连续工作数小时而不偏离计划。
- 跨平台使用者。 superpowers 支持 Claude Code、Codex CLI、Cursor、Gemini CLI、OpenCode 等八个平台。你在一个平台上写的 Skill 可以直接在另一个平台上用。这一点 gstack 也在做(支持十款 AI 编码工具),但 superpowers 的跨平台兼容性更成熟——它的 Skill 格式更标准化,触发机制不依赖平台特有的 hooks 系统。
不适合:
- 从零到一的绿野项目。 没有 CEO 角色审产品方向、没有设计师角色审用户体验、没有安全官角色审计漏洞——superpowers 缺乏 gstack 那种全景角色覆盖。做一个全新产品,你仍然需要自己判断"该不该做"和"做给谁用"。
- 需要完整治理轨迹的项目。 superpowers 的设计文档存在
docs/superpowers/specs/下,但没有像 gstack 或 OpenSpec 那样的结构化审查记录和审计轨迹。合规性行业的需求它满足不了。 - 小修小补。 brainstorming 流程强制"每个项目都要走设计流程",但改一个按钮颜色不值得九步设计流程。superpowers 的流程成本对小任务来说偏高——不像 Pocock Skills 那样可以单 Skill 快速调用。
一个实用的判断:任务是"写一个新功能"——superpowers 值回票价。任务是"做一个新产品"——gstack 更完整。任务是"修一个小 bug"——Pocock Skills 更快。
6.8 与前后章节的关系
superpowers 与 Skills(第 2 章)。 superpowers 的十四个 Skill 在格式上和 Pocock 的 Skill 没什么区别——都是 SKILL.md 文件,都有 metadata + description + body。核心差异在触发机制。Pocock 的 Skill 是手动调用的——你不说 /tdd,Agent 不用。superpowers 的 Skill 是自动触发的——Agent 读 description 匹配当前场景,自己决定激活哪个。Pocock 把控制权留给人,superpowers 把判断权交给 Agent。
superpowers 与 Ralph Loop(第 4 章)。 superpowers 的 subagent-driven-development 和 Ralph Loop 有相似的目标——让 Agent 自主完成多轮工作。但实现方式完全不同。Ralph Loop 是同一个 Agent 在同一个会话中反复迭代——Stop Hook 拦截退出,重新注入 prompt,Agent 看到自己上一轮的产出并改进。superpowers 是新 Agent 新上下文——每个任务派一个全新的子 Agent,上下文干净,不带历史噪音。前者的优势是可以累积理解,劣势是上下文膨胀。后者的优势是上下文干净,劣势是每个子 Agent 需要被精确构造上下文,对主 Agent 的协调能力要求更高。
superpowers 与 gstack(第 5 章)。 gstack 是人驱动流程,superpowers 是 Agent 驱动流程。gstack 靠角色覆盖质量,superpowers 靠工具覆盖质量。gstack 用系统 hooks 做门控,superpowers 用 prompt 内嵌指令做门控。两个系统解决的是同一个问题(如何让 AI Agent 高质量产出),走了相反的设计路径。
superpowers 与 autoresearch(第 7 章)。 autoresearch 的多 Agent 轮转和 superpowers 的子 Agent 派遣都涉及多 Agent 协作。但协作模式不同。autoresearch 是审查式协作——Agent A 实现,Agent B 审查并修复,Agent C 再审查并修复。superpowers 是分工式协作——每个子 Agent 负责一个独立任务,主 Agent 协调和审查。第 7 章会详谈这两种协作模式的差异。
6.9 本章小结
superpowers 拿到 201K+ Stars,不是因为运气——它的设计方向确实对:不靠流程锁住质量,靠足够多的 Skill 覆盖足够多的场景,靠自动触发让 Agent 在合适的时机用对的工具。
它的核心设计三条:
- 自动触发替代手动调用。 Skill 不是斜杠命令——你不需要记住什么时候该用什么。Agent 在读 description 时自己判断。技能的使用不再靠人类记忆,靠 Agent 自觉。
- 子 Agent 隔离替代上下文累积。 每个任务一个全新的子 Agent,上下文只包含完成当前任务所需的最小信息。这解决了 Ralph Loop 的循环膨胀问题——上下文不会随着迭代次数线性增长,每个子 Agent 都在干净的环境中工作。
- 认知门控替代系统门控。 gstack 用 PreToolUse hooks 在系统层面锁住行为。superpowers 用
<HARD-GATE>标签在 prompt 层面锁住行为。前者更强但依赖平台,后者更软但跨平台通用。两条路线验证了同一个结论:AI Agent 需要门控——它不能在任何时候做任何事。门控的实现在哪里(系统层还是 prompt 层),取决于你的平台能力和对 Agent 的信任程度。
gstack 是流程集成——二十三个角色在七个 Sprint 阶段中协作,输出靠流程结构保证。superpowers 是工具覆盖——十四个 Skill 在自动触发中组合,输出靠工具质量保证。第 7 章讲 autoresearch:连子 Agent 的协调也不要人了,从 Issue 到 PR 全自动,行不行?
留言板
欢迎在此分享你的想法!评论通过 GitHub Issues 存储,需要 GitHub 账号登录。