第4章:Ralph Loop —— 自主循环开发
"Ralph is a Bash loop."
——Geoffrey Huntley, 2025 年
这句话是对 Ralph Wiggum 技术最精确的定义。不是架构图,不是论文,不是 200 页的设计文档。就是一个 while 循环。把同一个 prompt 反复喂给 AI,让它看到自己上一轮的产出,然后改进。再改进。直到成功。
第 3 章讲了一件事:Spec 是你和 AI 之间的合约——它定义了"做成什么样才算对"。但合约签完了,履约过程仍然充满不确定性。AI Agent 第一次的实现可能偏离规格,第二次可能修好一个问题却引入另一个,第三次可能陷入"改动 A 破坏 B、修复 B 破坏 A"的死循环。
Ralph Loop 就是为这个场景设计的。如果 Spec 是"做到什么标准",Ralph Loop 就是"做不到就继续做"的执行引擎。它不是一个文档,不是一个 Skill,而是一个自主循环控制结构——把 AI Agent 从一次性助手变成了不知疲倦的初级工程师。
本章沿三条线索推进。第一条,Ralph Loop 的起源——一个《辛普森一家》的梗如何变成了 AI 软件工程的核心模式。第二条,Anthropic 官方的 ralph-wiggum 插件——用 Stop Hook 实现的会话内自指涉循环,这是目前最优雅的 Ralph Loop 实现。第三条,Ralph 生态中的其他实现。
自指涉(self-referential):AI 的产出变成自己的输入。不是把上一轮的输出文本喂给下一轮——而是 AI 在文件系统里读到自己刚写的代码,发现 bug,自己修。输入始终是同一个 prompt,但 AI 每次看到的文件系统都不一样,因为它上一轮已经改过一遍了。
4.1 起源:当 Ralph Wiggum 学会了循环
理解 Ralph Loop,要先理解 Ralph Wiggum。
Ralph Wiggum 是《辛普森一家》中的角色——一个永远乐观、永远搞不清状况的小男孩。他的经典台词"I'm helping!"通常发生在他正在把事情搞得更糟的时候。他不聪明。但他有一个特质:永不放弃。你让他做一件事,他会一直尝试,用各种奇怪的方式,直到偶然成功——或者直到有人阻止他。
2025 年初,澳大利亚开发者 Geoffrey Huntley 提出了一个观察:AI 编码 Agent 的行为模式和 Ralph Wiggum 惊人地相似。你给它一个任务,它生成代码,你告诉它"不对,这里有问题",它修改,你再告诉它"还是不对",它再修改。它不会主动停下来反思"我是不是从根本上理解错了?"它只会继续尝试。乐观、执着、缺乏元认知——和 Ralph 一模一样。

但 Huntley 的洞见不止于讽刺。他指出:Ralph 的问题不在于"一直尝试",在于没有人在循环中告诉他什么是成功。如果你给 Ralph 一个明确的成功标准和一个自动化的循环控制结构——"做到这个标准就停,否则继续试"——Ralph 的执着就从 bug 变成了 feature。
这就是"Ralph Wiggum 技术"(后简称为 Ralph Loop)的核心理念。Huntley 用一句话定义了它:"Ralph is a Bash loop." 就是字面意思——一个 while 循环。
while :; do
cat PROMPT.md | claude-code --continue
done
这个循环简单到没人相信它能工作。但它确实能。关键不在循环本身——在于自指涉(self-referential)的机制:每次循环中,Claude Code 接收的不是上一轮的输出,而是和第一轮完全相同的 prompt。但 Claude 看到的东西变了——它的上一轮工作已经持久化在文件系统和 git 历史中。它读到自己的代码,发现 bug,修复,跑测试,看到失败,再修复。所有这些都发生在一个 while 循环的连续迭代中,但每一次迭代的上下文都在演进。
Huntley 的原始实现是一个只有几行的 Bash 脚本。把它工程化、做成可复用产品的,是 Anthropic 的 Claude Code 团队。
4.2 Anthropic ralph-wiggum 插件:Stop Hook 的魔法
ralph-wiggum 是 Anthropic 官方维护的 Claude Code 插件,利用 Stop Hook 机制在会话内部实现自指涉循环。它不是外部脚本——安装后,/ralph-loop 命令在你当前会话中直接可用。
这个设计选择很关键。frankbria 的 ralph-claude-code 是一个外部 Bash 脚本,它启动一个新的 Claude Code 进程、等它结束、检查输出、决定是否启动下一个。Anthropic 的 ralph-wiggum 插件则完全不同——循环发生在你的当前会话内部。你启动一个 /ralph-loop,然后你就在这个会话中不断迭代,直到完成。不需要 fork 子进程,不需要解析 RALPH_STATUS 块,不需要管理进程生命周期。
4.2.1 安装
ralph-wiggum 不随 Claude Code CLI 自带——需要主动安装。一条命令:
/plugin install anthropics/ralph-wiggum
安装后,插件存放在 ~/.claude/plugins/ralph-wiggum/,/ralph-loop 斜杠命令随即可用。卸载也很干净:
/plugin remove ralph-wiggum
关于"内置"的澄清:本章最初称 ralph-wiggum 为"Claude Code 内置插件",这个表述不够精确。更准确的说法是——它是 Anthropic 官方开发的原生插件,深度利用 Claude Code 的 Stop Hook 基础设施,因此能和会话上下文无缝协作。但在发行层面上,它独立于 CLI 安装包,需要用户主动安装。类似地,第 2 章提到的 /tdd、/diagnose 等 Skill 也对应独立的可安装插件,不是自带的。
4.2.2 核心机制:Stop Hook 拦截退出
ralph-wiggum 插件的核心是一个 Stop Hook 脚本——hooks/stop-hook.sh。理解这个 Hook 做了什么,就理解了整个插件的设计。
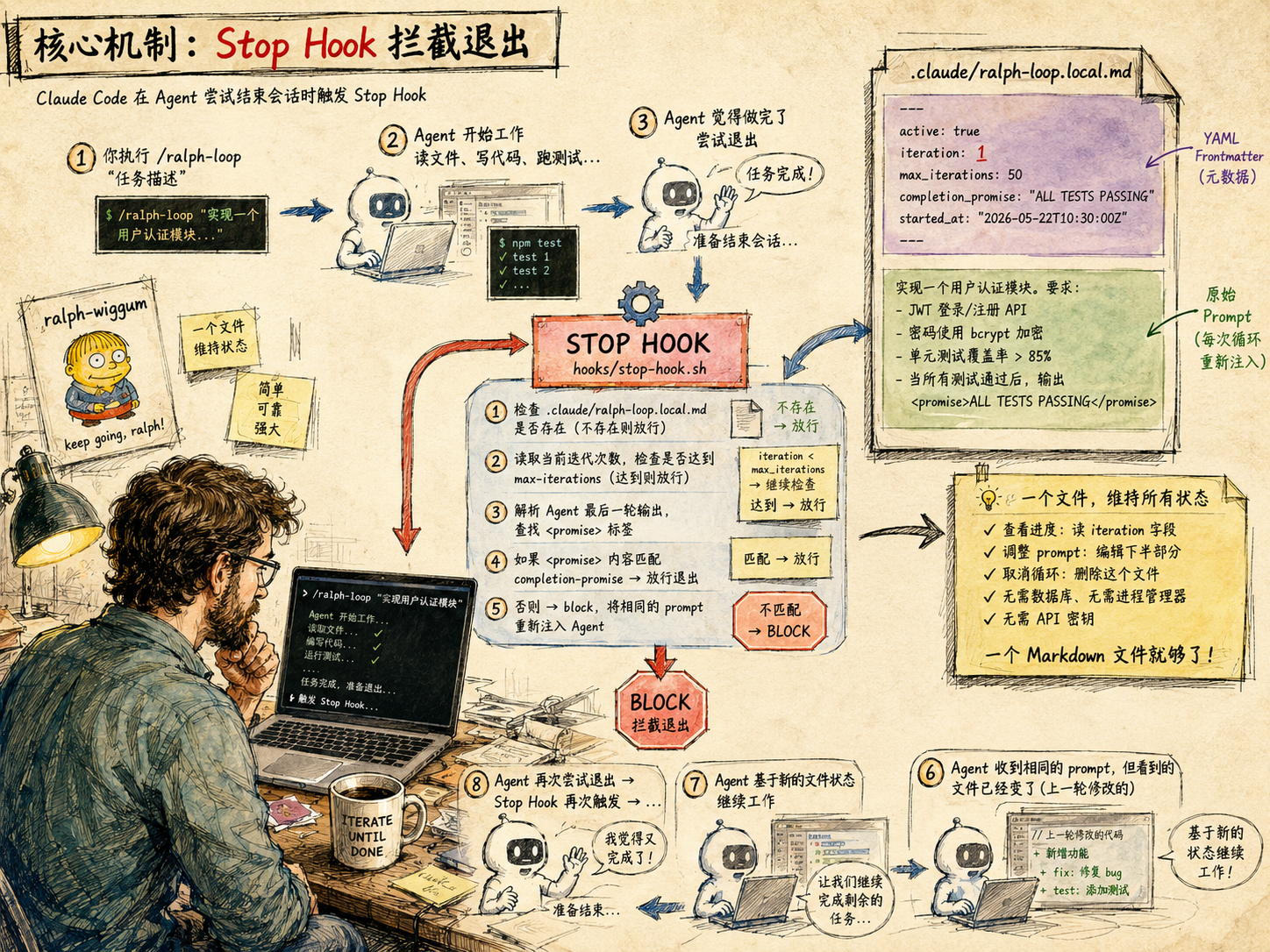
在 Claude Code 中,Stop Hook 在 Agent 尝试结束会话时触发。正常情况下,Agent 完成任务后输出结果,会话结束。但如果 Stop Hook 返回 "decision": "block",Agent 就被阻止退出——它的上下文会保留,但会被要求继续工作。
ralph-wiggum 的 Stop Hook 正是利用了这个机制:
你执行 /ralph-loop "任务描述"
↓
Agent 开始工作(读文件、写代码、跑测试)
↓
Agent 觉得做完了,尝试退出
↓
Stop Hook 触发 →
① 检查 .claude/ralph-loop.local.md 是否存在(不存在则放行)
② 读取当前迭代次数,检查是否达到 max-iterations(达到则放行)
③ 解析 Agent 最后一轮输出,查找 标签
④ 如果 内容匹配 completion-promise → 放行退出
⑤ 否则 → block,将相同的 prompt 重新注入 Agent
↓
Agent 收到同样的 prompt,但看到的文件已经变了(上一轮修改的)
↓
Agent 基于新的文件状态继续工作
↓
Agent 再次尝试退出 → Stop Hook 再次触发 → ...
整个流程中只有一个文件在维持状态:.claude/ralph-loop.local.md。一个 Markdown 文件,使用 YAML frontmatter 存储循环元数据:
---
active: true
iteration: 1
max_iterations: 50
completion_promise: "ALL TESTS PASSING"
started_at: "2026-05-22T10:30:00Z"
---
实现一个用户认证模块。要求:
- JWT 登录/注册 API
- 密码使用 bcrypt 加密
- 单元测试覆盖率 > 85%
- 当所有测试通过后,输出 ALL TESTS PASSING
文件分为两部分。上半部分是 YAML frontmatter——iteration、max_iterations、completion_promise——由 Stop Hook 读取和更新。下半部分是原始 prompt——每次循环时原样重新注入给 Agent。
整个循环的状态仅由这一个文件定义。要取消循环?删除这个文件。要查看进度?读这个文件的 iteration 字段。要调整 prompt?编辑下半部分。不需要数据库、不需要进程管理器、不需要 API 密钥——一个 Markdown 文件就够了。
4.2.3 两个出口条件:Promise 与 Max-Iterations
ralph-wiggum 提供两种退出机制,对应两种使用场景。
Completion Promise:语义完成信号。 通过 --completion-promise 参数设置一个短语。当 Agent 认为自己完成了任务,它必须输出:
ALL TESTS PASSING
Stop Hook 从 Agent 的最后一轮输出中提取 <promise> 标签的内容,与预设的 completion-promise 做精确字符串匹配。匹配成功,循环退出。匹配失败——或者没有输出 <promise> 标签——循环继续。
这个设计有一个巧妙的副作用:"完成"的定义从 Hook 脚本转移到了 prompt 本身。你不需要修改 Hook 代码来定义"什么算完成"——你在 prompt 中写清楚,然后设置一个对应的 promise 短语。当 AI 判断验收标准已满足、输出 promise 标签时,循环自然结束。
但这也引入了一个信任问题:AI 会不会撒谎?如果 Agent 陷入了死循环,它会不会输出一个假的 <promise> 来"逃脱"?ralph-wiggum 的 prompt 模板中有一段严厉的指令:
CRITICAL RULE: If a completion promise is set, you may ONLY output it when the statement is completely and unequivocally TRUE. Do not output false promises to escape the loop, even if you think you're stuck or should exit for other reasons. The loop is designed to continue until genuine completion.
这段指令的效果取决于模型的遵循能力。在 Claude 4.x 系列模型上,promise 机制表现良好——模型倾向于诚实地报告完成状态。但这仍然是一个软约束,不是硬门禁。如果任务本身就定义不清,AI 可能会真诚地相信自己完成了却没有——这不是撒谎,是判断力不足。
Max-Iterations:硬性迭代上限。 --max-iterations 是一个纯粹的工程安全阀。不管 Agent 输出什么,不管任务是否完成,循环到达指定次数就退出。官方文档的说法很直接:
Always use
--max-iterationsas a safety net to prevent infinite loops on impossible tasks.
这不是"推荐",是必须。没有 --max-iterations 且没有 --completion-promise 的 Ralph Loop 会永远运行。在设计上这是一个 feature("不加限制就是真的无限循环"),但在实践中几乎总是需要设一个上限。
两者的关系是 OR:循环在 (promise 匹配) 或 (达到 max-iterations) 时退出。promise 是理想出口——任务真正完成了。max-iterations 是安全出口——不管完成没有,该停了。
4.2.4 会话内循环 vs 外部进程循环
ralph-wiggum 的"会话内循环"设计与 frankbria 的"外部进程循环"代表了 Ralph Loop 的两种架构哲学。
| 维度 | Anthropic ralph-wiggum(会话内) | frankbria ralph-claude-code(外部进程) |
|---|---|---|
| 循环位置 | Stop Hook 拦截退出,同会话内继续 | Bash 脚本 fork 新 Claude Code 进程 |
| 状态持久化 | 单个 .claude/ralph-loop.local.md 文件 | 多个状态文件 (.exit_signals, status.json 等) |
| 上下文连续性 | 会话上下文持续累积(Agent 记得之前的所有交互) | 每轮启动新进程,上下文从文件重新加载 |
| 安全机制 | max-iterations + promise 匹配 | 熔断器 (CLOSED/HALF_OPEN/OPEN) + 速率限制 |
| 人工介入 | 可以在会话中随时观察和对话式干预 | 通过 ralph-monitor 观察,较难交互式介入 |
| 安装复杂度 | 需要安装插件(/plugin install) | 需要安装 Bash 脚本和依赖 |
| 适用场景 | 交互式迭代、人在旁边的半自主开发 | 无人值守的夜间长任务 |
两种架构没有绝对的优劣。会话内循环的优势在于上下文连续——Agent 在每一轮中都能看到之前所有轮次和人类的交互。你可以在循环过程中随时插话:"等一下,这里的设计思路不对,应该改成……"Agent 收到指令,调整方向,继续迭代。你像一个师傅在旁边看着徒弟干活,偶尔纠正一下。
外部进程循环的优势在于隔离性和鲁棒性——每一轮是一个全新的进程,不会累积上下文膨胀的问题。frankbria 的方案还提供熔断器和速率限制,适合真正的无人值守场景。代价是失去了人在循环中的灵活性。
一个实用的选择策略:白天用 ralph-wiggum——你坐在旁边,有问题随时纠正。晚上用 frankbria——设好 max-iterations 和熔断器参数,早上看结果。
4.2.5 Prompt 编写的最佳实践
ralph-wiggum 的效果高度依赖于 prompt 的质量。官方 README 给出了四条核心原则,每一条都指向一个常见的失败模式。
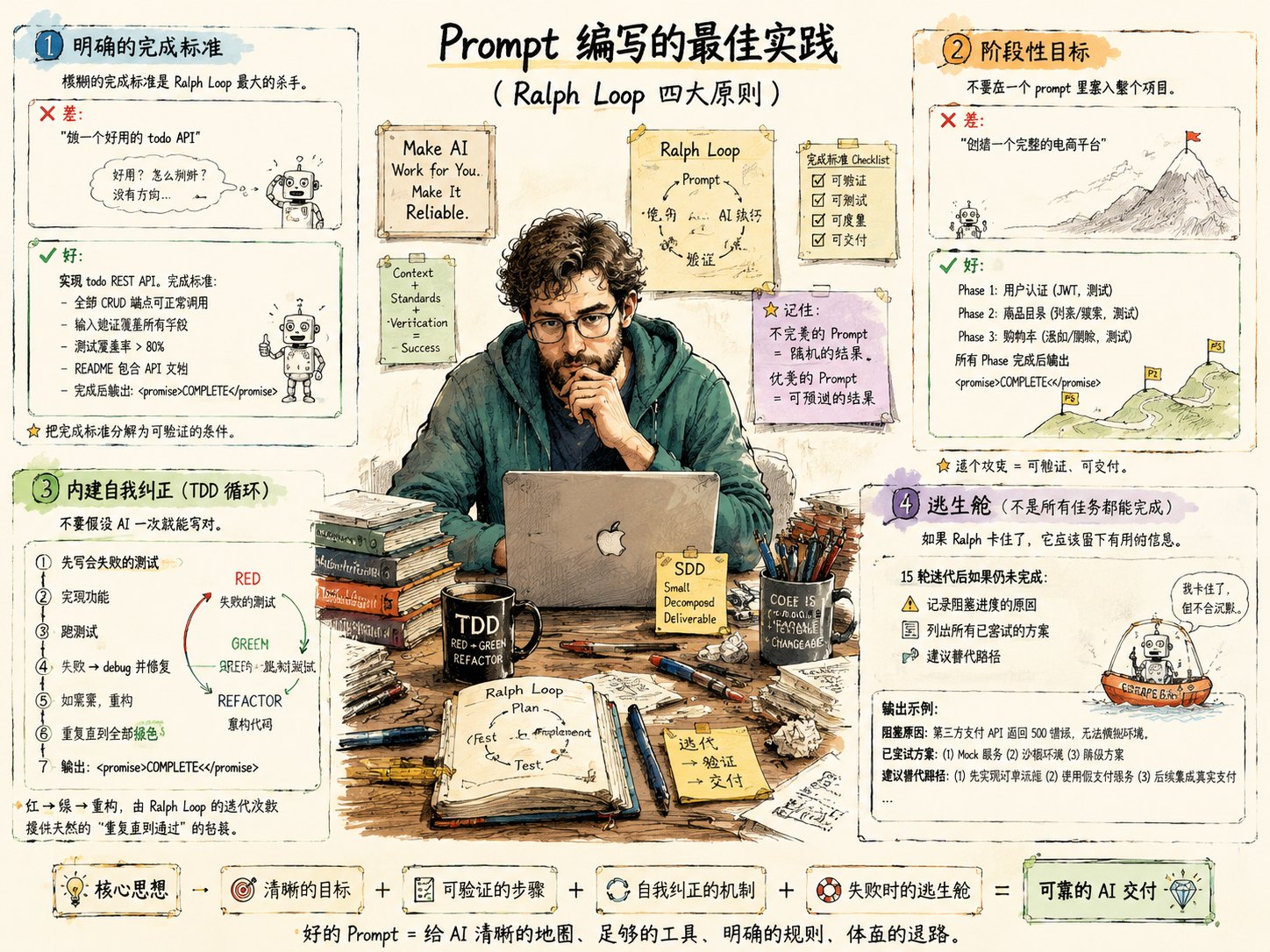
原则 1:明确的完成标准。 模糊的完成标准是 Ralph Loop 最大的杀手。AI 不知道自己在朝什么方向努力,就会在随机方向上消耗所有的迭代配额。
❌ 差: "做一个好用的 todo API"
✅ 好: "实现 todo REST API。完成标准:
- 全部 CRUD 端点可正常调用
- 输入验证覆盖所有字段
- 测试覆盖率 > 80%
- README 包含 API 文档
- 完成后输出: COMPLETE "
差的 prompt 把判断"好不好"的责任推给了 AI——它不具备这个判断力。好的 prompt 把完成标准分解为可验证的条件——每个条件都可以被自动化测试、linter 或人工检查确认。
原则 2:阶段性目标。 不要在一个 prompt 里塞入整个项目。拆成阶段,让 Ralph 逐个攻克:
❌ 差: "创建一个完整的电商平台"
✅ 好: "Phase 1: 用户认证 (JWT, 测试)
Phase 2: 商品目录 (列表/搜索, 测试)
Phase 3: 购物车 (添加/删除, 测试)
所有 Phase 完成后输出 COMPLETE "
这条原则和第 3 章 SDD 中"一个变更一个文件夹"的粒度原则一致。Ralph Loop 的一次迭代大约对应 SDD 的一个变更——能在一个上下文窗口内完成、有独立的验收标准、产出可验证的结果。
原则 3:内建自我纠正。 不要假设 AI 一次就能写对。在 prompt 中嵌入 TDD 循环:
❌ 差: "写 feature X 的代码"
✅ 好: "用 TDD 实现 feature X:
1. 先写会失败的测试
2. 实现功能
3. 跑测试
4. 如果失败,debug 并修复
5. 如果需要,重构
6. 重复直到全部绿色
7. 输出: COMPLETE "
这个设计和第 2 章中 Pocock 的 /tdd Skill 完全一致——红→绿→重构循环,由 Ralph Loop 的迭代次数提供天然的"重复直到通过"的包装。/tdd 做一轮,Ralph Loop 做 N 轮。
原则 4:逃生舱。 不是所有任务都能完成。如果 Ralph 卡住了,它应该留下有用的信息而不是沉默地消耗配额:
"15 轮迭代后如果仍未完成:
- 记录阻塞进度的原因
- 列出所有已尝试的方案
- 建议替代路径"
这条原则对应了第 2 章 /diagnose 中的 Phase 4——不是盲目重试,而是结构化地报告"我做了什么、为什么没成功、接下来可以尝试什么"。
4.2.6 实际效果
ralph-wiggum 有记录在案的成功案例:
- YC hackathon 测试:在 Y Combinator 的 hackathon 中,Ralph 在一夜之间自主生成了 6 个完整仓库。
- $50k 合约:一个价值 5 万美元的开发合同,Ralph 以 $297 的 API 成本完成了全部实现——约 0.6% 的成本占比。
- "cursed" 编程语言:一位开发者使用 Ralph Loop,在 3 个月内完全通过自主迭代创建了一整门编程语言。
这些结果的共同特征是:任务定义清晰、验收标准可自动化验证、人设置了合理的 max-iterations 上限。没有哪个项目是靠"做一个好东西"这样的模糊 prompt 成功的。
4.2.7 实战:用 Ralph Loop 开发网页版贪吃蛇
原则讲完了。来看一个实际例子——用 Ralph Loop 开发网页版贪吃蛇。
选贪吃蛇是因为它的验收标准天然适合自动化验证。蛇能不能移动、能不能吃食物、撞墙会不会死、分数对不对——全都可以写成 assert 语句,不需要人工判断。这正是 Ralph Loop 最擅长的场景。
先看 prompt。
两种输入方式:文件与对话。
文件方式:把 prompt 保存为 .claude/ralph-loop.local.md,然后执行 /ralph-loop(不带参数)。插件自动读取文件中的 YAML frontmatter 和 prompt 内容,启动循环。这是 Anthropic 官方文档推荐的方式——prompt 可以版本控制、反复使用、团队共享。上面的安装流程、prompt 编写原则、和这个贪吃蛇例子,采用的都是文件方式。
对话方式:直接在对话框中输入:
/ralph-loop --max-iterations 20 --completion-promise "SNAKE_GAME_COMPLETE" "创建一个网页版贪吃蛇游戏..."
官方 README 中的 Quick Start 示例用的就是对话方式——一条命令带上所有参数和 prompt。对话方式适合一次性探索任务:你脑子里蹦出一个想法,不想切出去建文件,直接在聊天框里敲完就开跑。但 prompt 不会被持久化——换一台机器、重建环境后,这个 prompt 就丢失了。
以下示例采用文件方式——原因有二。一是贪吃蛇的验收标准足够长,放在文件里更整洁,不会被 CLI 的引号转义折磨。二是一个写好的 .claude/ralph-loop.local.md 本身就是一份"可执行的 Spec"——它既是给 AI 的任务说明书,也是循环的控制文件。把它放到项目仓库里,任何团队成员拉下来就能重现这个自主开发过程。
---
active: true
iteration: 1
max_iterations: 20
completion_promise: "SNAKE_GAME_COMPLETE"
started_at: "2026-05-22T14:00:00Z"
---
创建一个网页版贪吃蛇游戏,所有代码放在 snake-game/ 目录下。
核心功能:
- 20x20 网格画布,蛇用绿色方块,食物用红色方块
- 方向键控制蛇的移动
- 吃到食物后蛇身变长 1 格,食物随机刷新
- 撞墙或撞到自己 → 游戏结束,显示得分
- 按空格键重新开始
技术要求:
- 纯 HTML/CSS/JS,单文件 index.html,不依赖任何框架
- 游戏循环用 requestAnimationFrame,初始速度 150ms/步
- 所有 DOM 操作用原生 API
验收标准:
- 打开 index.html 后能看到 20x20 网格和一条初始长度为 3 的蛇
- 按方向键蛇能正确移动,不能反向(比如向右时不能直接按左)
- 蛇头碰到食物时蛇身变长,食物出现在新位置(不在蛇身上)
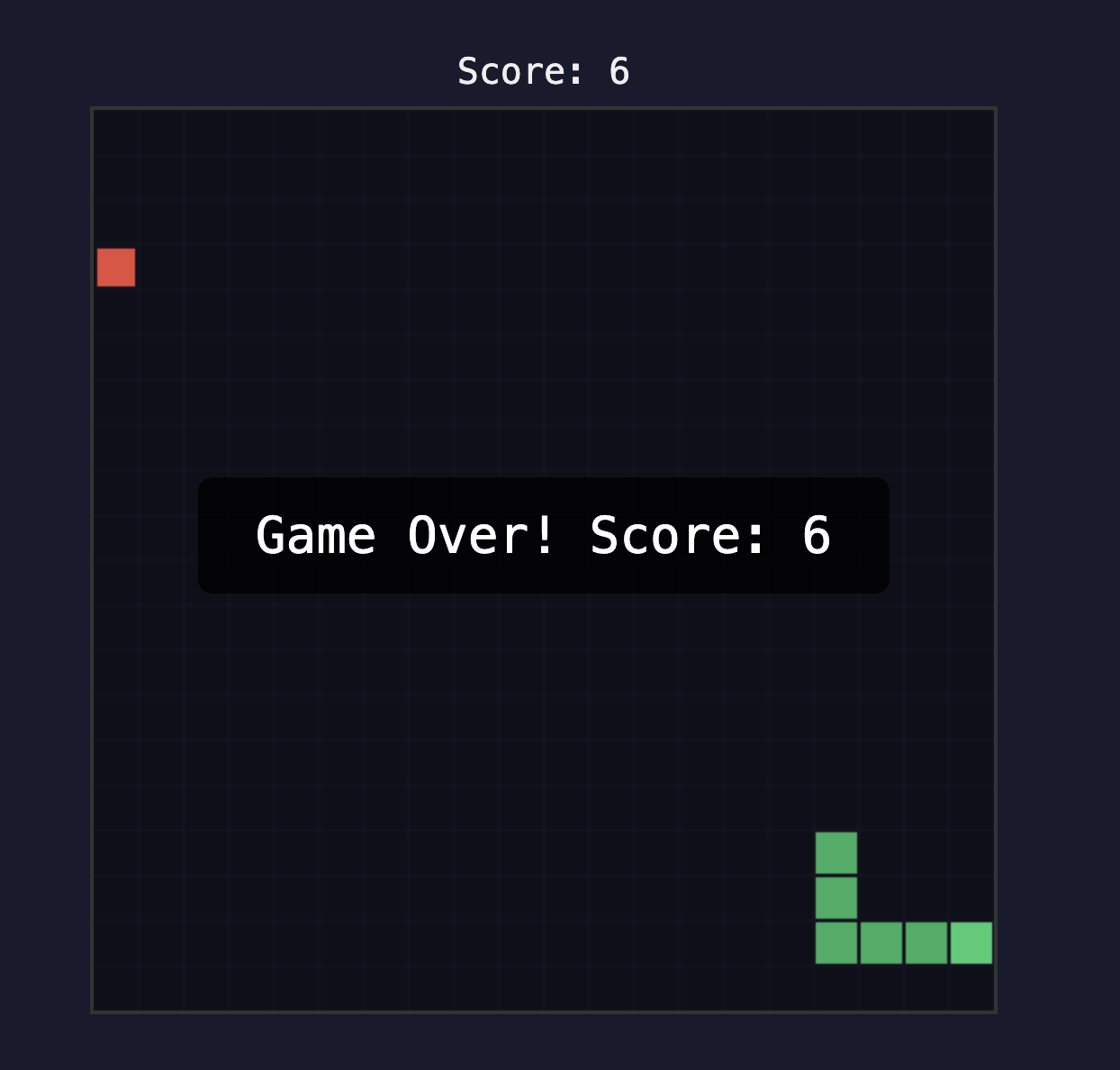
- 蛇头碰到边界或蛇身时游戏停止,弹出 "Game Over! Score: X"
- 按空格键游戏重置为初始状态
- 以上所有行为通过自动化测试验证(test.html)
完成后输出:SNAKE_GAME_COMPLETE
这个文件就是 4.2.2 节说的那个状态文件。上半部分的 YAML frontmatter 定义循环参数——最多跑 20 轮,完成信号是 SNAKE_GAME_COMPLETE。下半部分是任务本身——每次循环中 Stop Hook 原样重新注入给 Agent。
已开始运行 /ralph-loop失败了,因为没有设置
CLAUDE_PLUGIN_ROOT, 我告诉它CLAUDE_PLUGIN_ROOT=/Users/smallnest/.claude后就正常运行了。
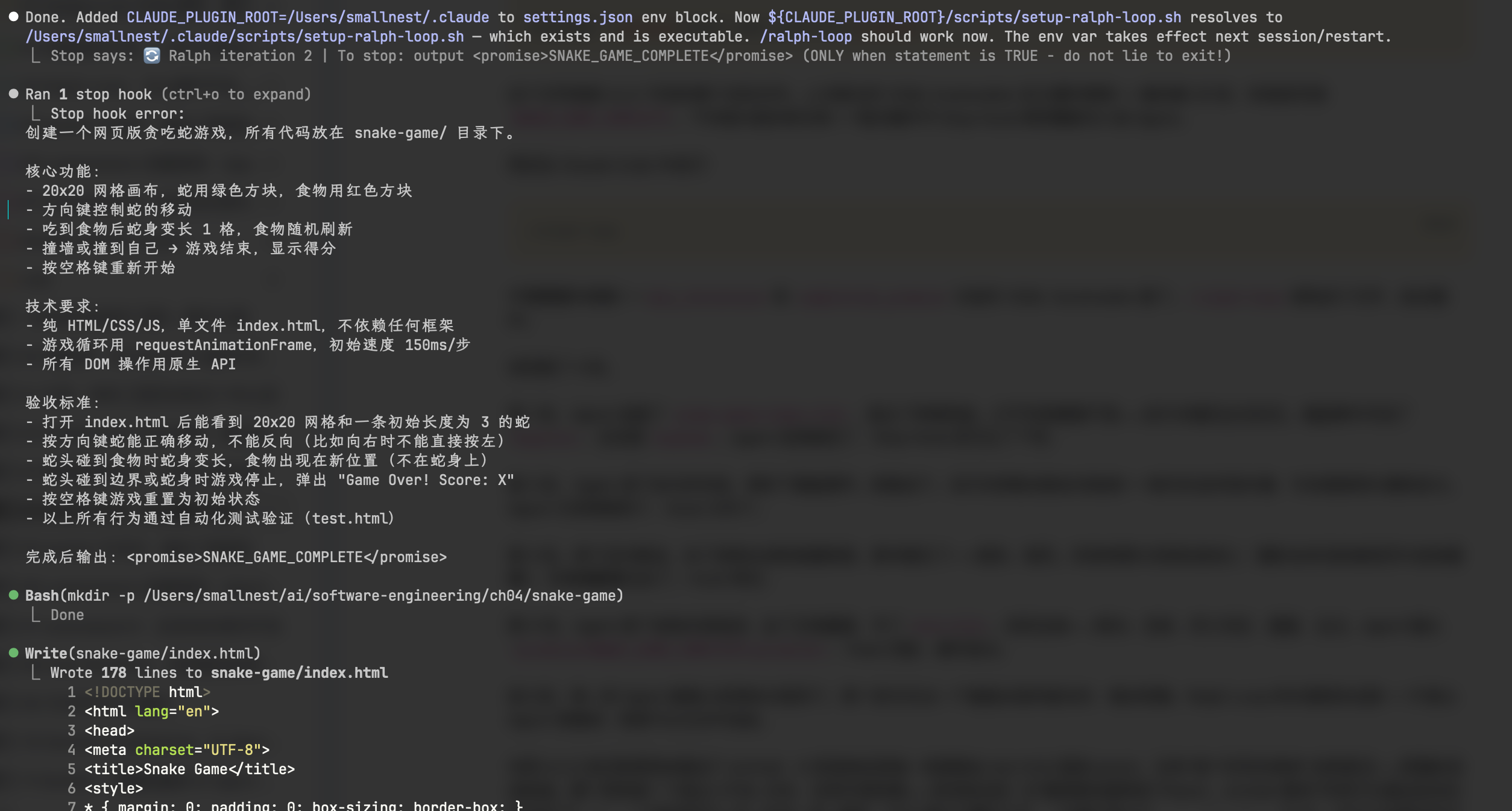
然后在 Claude Code 中执行:
/ralph-loop
不需要额外参数——max_iterations 和 completion_promise 已经在 YAML frontmatter 里了。/ralph-loop 读到这个文件,启动循环。
实际跑了 4 轮。
第 1 轮,Agent 创建了 snake-game/index.html,画出了网格和蛇。打开页面看着不错——按方向键完全没反应。键盘事件写成了 keypress,应该是 keydown。Agent 觉得做完了,Stop Hook 把它拦了下来。
第 2 轮,Agent 读了自己的代码,修好了键盘事件。蛇能动了。但方向控制没做反向检测——蛇向右走时按左键,它会直接掉头撞到自己。Agent 又觉得做完了,Hook 又拦了。
第 3 轮,修了反向移动,加了食物生成和碰撞检测。基本能玩了——能吃、能死。但食物偶尔会刷在蛇身上(随机坐标没检查是否与蛇身重叠),空格键重置也忘了。Hook 再拦。
第 4 轮,Agent 修了食物冲突检测,加了空格重置,写了 test.html。测试全绿——移动、进食、死亡判定、重置,全过。Agent 输出 <promise>SNAKE_GAME_COMPLETE</promise>,Hook 匹配,循环退出。
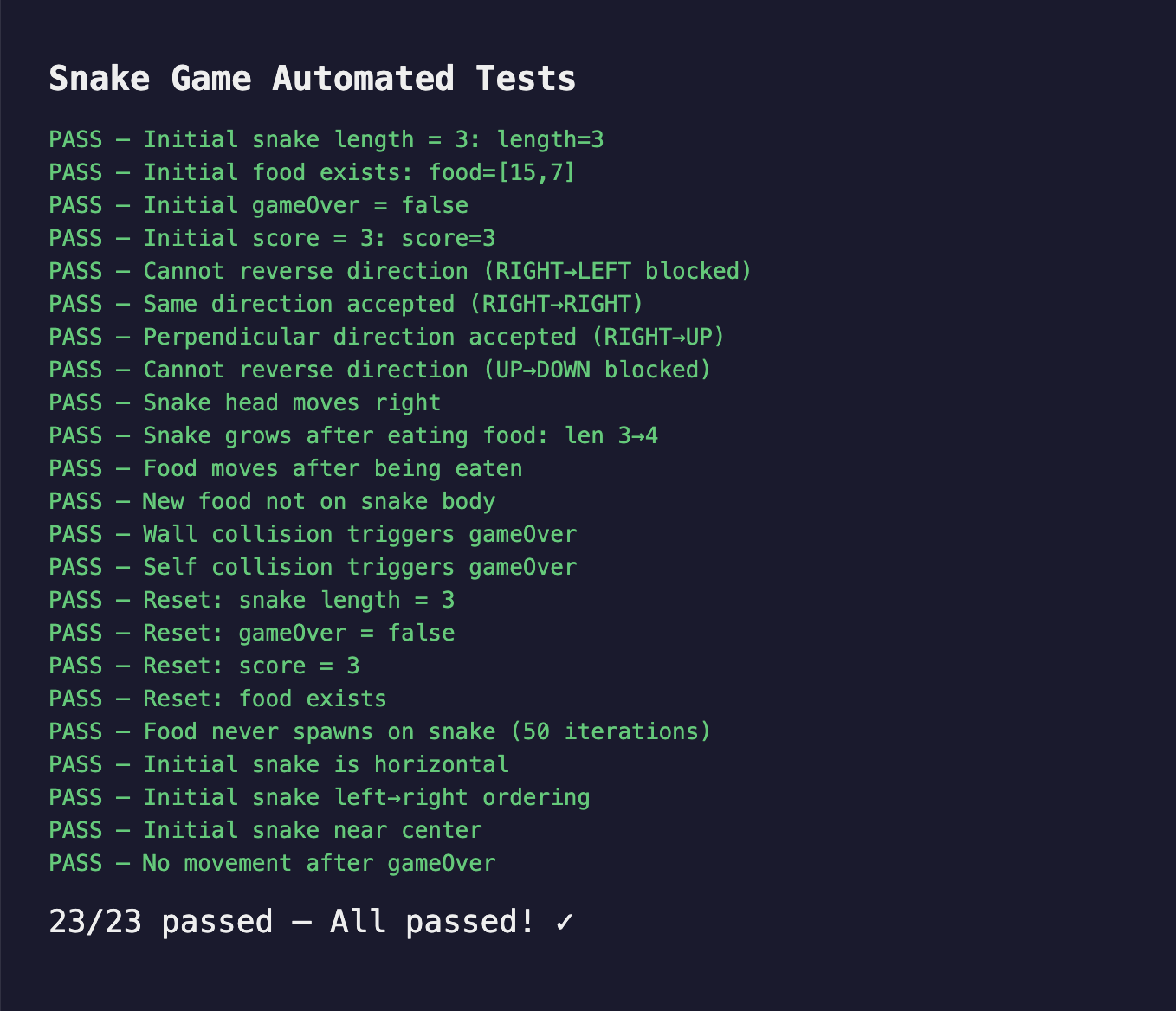
前三轮,每一轮 Agent 都真心觉得自己做完了。第 1 轮它交出一个键盘无效的版本时,毫无犹豫。Ralph Loop 的价值就在这里——不是让 Agent 变聪明,而是不让它交半成品。
对照 4.2.5 的四条原则来看这个 prompt:6 条验收标准每一条都能在 test.html 里跑 assert,没有"做个好玩的游戏"这种废话——明确的完成标准。整个游戏是一个独立 HTML 文件,没有外部依赖——阶段性目标(扩展到联机版再拆 Phase)。prompt 要求"所有行为通过自动化测试验证",Agent 只能写测试→跑→失败→修→再跑,TDD 循环自然转起来——内建自我纠正。max-iterations 设 20,对这个体量的游戏绰绰有余——逃生舱。
贪吃蛇的每个需求——蛇的位置、食物的位置、游戏状态——都能翻译成 assert 语句。这种"验收标准可程序化验证"的任务,Ralph Loop 几乎是稳的。反过来,如果 prompt 只写"做一个好玩的游戏",Ralph 第 1 轮就会输出 <promise>COMPLETE</promise>。它不是偷懒——它真不知道"好玩"是什么意思。
4.3 Ralph 生态:不止一种包法
Anthropic 的 ralph-wiggum 插件是"会话内循环"路线最优雅的实现,但不是唯一的。Ralph Loop 催生了一个小型生态——不同的开发者用不同的架构复现了同一个核心模式。
4.3.1 frankbria/ralph-claude-code:外部进程循环的代表
frankbria 的项目(9,000+ Stars)是 Ralph Loop 最早的工程化实现之一。它采用外部 Bash 脚本包装 Claude Code CLI 的架构,每次循环启动一个新的 Claude Code 进程。它的核心贡献在安全机制——引入了熔断器模式(CLOSED → HALF_OPEN → OPEN 三段状态机)、速率限制(默认 100 调用/小时)、以及通过 prd.json 实现的结构化故事拆分。适合需要无人值守运行数小时的场景。
4.3.2 michaelshimeles/ralphy:多 Agent 轮转
ralphy(2,868 Stars)的核心差异在于模型多样性——它在循环中轮转使用 Claude Code、Codex、OpenCode、Cursor Agent、Qwen、Droid 等多种 AI 编码工具。假设是:不同模型有不同盲区,轮转使用可以覆盖更多问题类型。这个思路和第 7 章 autoresearch 的"多 Agent 交叉审核"一脉相承。
4.3.3 AnandChowdhary/continuous-claude:Ralph Loop + PR 流程
continuous-claude(1,336 Stars)补齐了 Ralph Loop 的交付缺口——在循环结束后自动创建 PR、等待 CI 通过、Squash Merge。它的哲学和第 8 章 Goal Workflow 的 /ship-it 完全一致:如果代码的验证是自动化的,为什么合入不能是自动化的?
4.3.4 snwfdhmp/awesome-ralph:知识的索引
awesome-ralph(886 Stars)是一个精心整理的资源列表,索引了 Ralph 技术的所有项目、文章、工具和讨论。它的存在本身就说明 Ralph Loop 已经从一个开发者的 Bash 脚本演变为一个有社区、有词汇、有知识积累的工程模式。
4.4 Ralph Loop 的适用场景与局限性
Ralph Loop 不是万能药。它的有效性高度依赖于任务的特征。

4.4.1 最佳场景
有清晰验收标准的任务。 Ralph 的核心假设是"完成与否可以被程序化地或标签化地判断"——通过 promise 标签匹配或 max-iterations 上限。验收标准越可量化("所有测试通过"、"linter 零警告"、"API 返回 200 且响应体符合 schema"),AI 越能诚实地判断自己是否完成。
自包含的功能开发。 一个独立的 CRUD API、一个无需外部依赖的 UI 组件、一个纯算法的库函数——变更范围明确,影响面可控。Ralph 不需要理解"这个改动会怎么影响其他五个微服务"。
需要迭代优化的任务。 测试驱动开发、性能调优、代码重构——这些任务天然需要"做一轮 → 验证 → 改进"的循环。Ralph Loop 把这个循环自动化了。
适合无人值守的长任务。 大型重构、全项目依赖升级、跨文件的一致化修改——人类不想盯着屏幕做的事,Ralph 可以在你睡觉时跑。前提是设好了 --max-iterations 和 promise。
4.4.2 局限性
不适合需要架构决策的任务。 "应该用微服务还是单体?""数据用 SQL 还是 NoSQL?"——这类问题不是实现细节,是方向选择。Ralph Loop 能做的是在给定方向上持续优化,但它不能评估方向本身是否正确。
可能产生循环膨胀。 AI 在第一轮实现了基本可用的功能。第二轮它修 bug 时引入了性能问题。第三轮优化性能时破坏了 API 兼容性。第四轮修兼容性时重构了底层数据结构。每一轮都在"解决问题",但整体的代码复杂度在累积。max-iterations 只能限制轮次,无法检测"在错误的方向上前进"。
prompt 质量决定上限。 这是 Ralph Loop 最大的前置成本。写好一个能让 AI 在 50 轮内持续产出有价值代码的 prompt,本身就是一项需要练习的技能。Huntley 的原话是:"Operator skill matters. Success depends on writing good prompts, not just having a good model."
不适合需要人类判断的任务。 Ralph Loop 可以帮你实现代码,但它不会告诉你这个功能是不是用户真正需要的。它可以验证验收标准,但它不会质疑这个验收标准是不是反映了正确的用户需求。自主循环开发把编码环节自动化了,但产品决策仍然需要人类的判断力。
4.5 与前后章节的关系
Ralph Loop 与 Skill(第 2 章)。 Skill 是"怎么做一件事"的能力单元,Ralph Loop 是"如果一次没做成就再做一次"的执行策略。你可以在 Ralph Loop 的 prompt 中嵌入 Skill 指令——"使用 TDD 方法实现,每轮先写测试再写代码"——相当于在循环中激活了 /tdd Skill。Skill 提供方法论,Ralph Loop 提供执行力。
Ralph Loop 与 Spec(第 3 章)。 Spec 定义了"完成的标准",Ralph Loop 是达到这个标准的执行引擎。两者是合约与履约的关系。在有 Spec 的情况下用 Ralph Loop,Agent 知道终点在哪——Spec 中的验收标准可以直接转化为 prompt 中的验收标准和 promise 短语。在没有 Spec 的情况下用 Ralph Loop,Agent 在黑暗中奔跑。
Ralph Loop 与 autoresearch(第 7 章)。 autoresearch 在 Ralph Loop 的基础上加入了两个关键创新:多 Agent 轮转交叉审核(不同模型审不同模型的产出)和双轨质量门禁(硬门禁 Build/Lint/Test + 软门禁 LLM 评分 ≥ 85)。可以把 Ralph Loop(尤其是 Anthropic 的 ralph-wiggum 插件)理解为 autoresearch 的单 Agent 精简版。
Ralph Loop 与 Goal Workflow(第 8 章)。 /goal 是"单次会话完成一个 Issue",Ralph Loop 是"多轮迭代完成一个任务"。/goal 的哲学是"每次只做一件事,把它做好";Ralph Loop 的哲学是"如果一次做不好,就继续做,直到做好为止"。两者互补——/goal 适合拆分好的、能在一个上下文窗口内完成的独立变更,Ralph Loop 适合需要多轮迭代优化才能达标的任务。/goal 是Codex、Claude Code、Antigravity CLI新推出的斜杠命令。
4.6 本章小结
Ralph Loop 的名字来源于一个《辛普森一家》中永远搞不清状况的角色。Huntley 用一句话定义了它——"Ralph is a Bash loop"——一个谁都能看懂的 while 循环。Anthropic 用 Stop Hook 把它变成了 Claude Code 的原生能力——一个 Markdown 状态文件 + 一个 Hook 脚本 = 一个完整的自主循环开发系统。
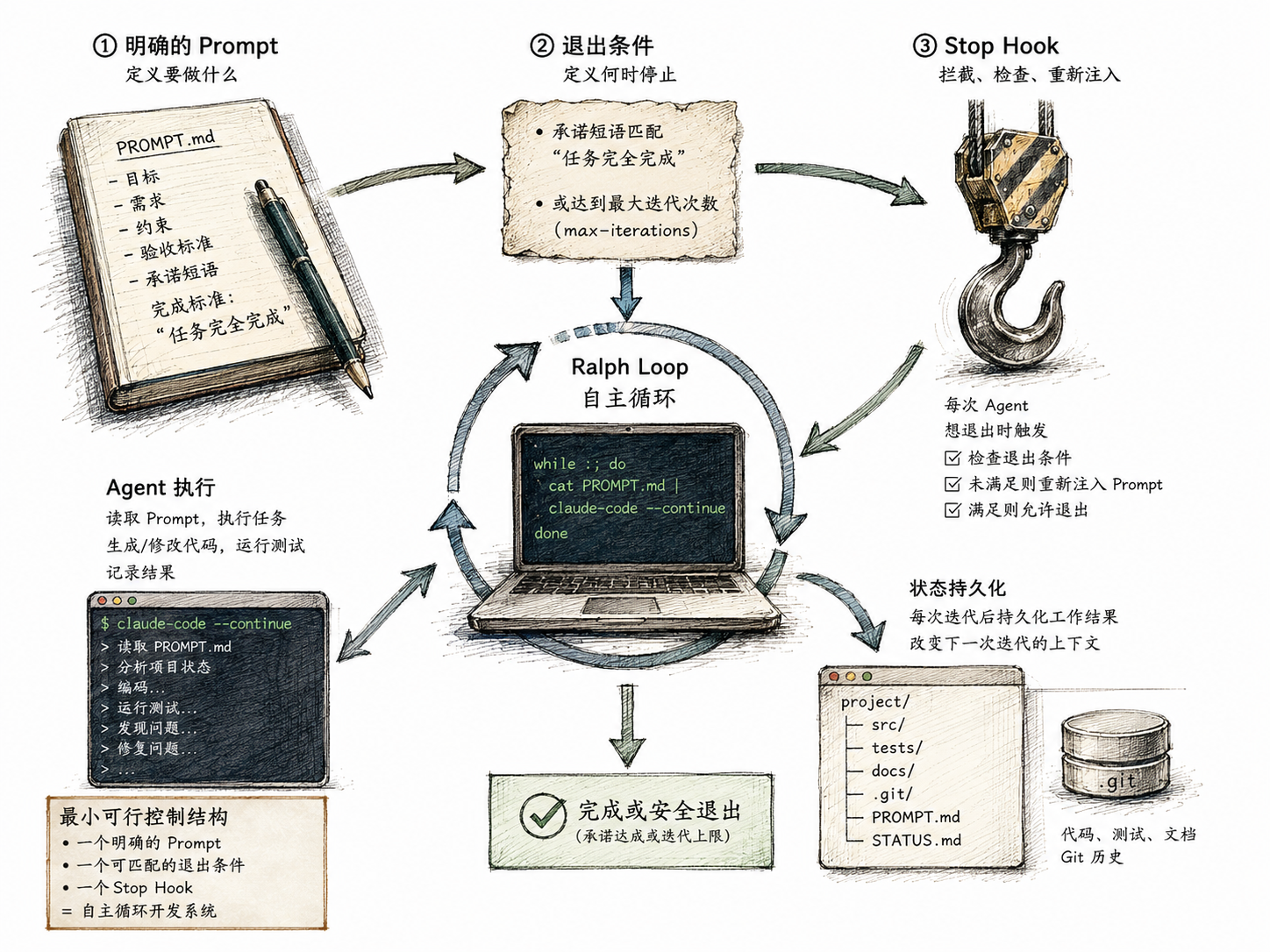
它的核心贡献不在于技术复杂度(核心循环不超过 200 行 Bash),而在于它找到了人类意图和 AI 执行之间的最小可行控制结构:
- 把"要做什么"写在一个 prompt 里
- 把"做完的信号"定义为一个 promise 短语或 max-iterations 上限
- 让 Stop Hook 在每次 Agent 想退出时拦截、检查、重新注入 prompt
- 循环直到完成或安全退出
这个结构的好处是简单。它没有引入新的 AI 范式、不需要复杂的多 Agent 编排、不依赖任何特定的模型或平台。它只需要三个东西——一个明确的 prompt、一个可匹配的退出条件、和一个 Hook。
如果第 2 章的 Skill 是能力单元、第 3 章的 Spec 是质量合约,那么 Ralph Loop 就是执行引擎。它不让 AI 变得更聪明——它让 AI 的失败变得可管理。当你可以安全地让 AI 一直尝试直到成功,AI 的不可靠性就不再是 bug——它是系统的一个已知参数,Ralph Loop 就是这个参数的补偿器。
Ralph Loop 解决了"一个 AI Agent 如何自主完成一个任务"的问题。但如果一个任务的规模超出了单 Agent 的能力——需要多个专家角色、多阶段流水线、跨角色的审查和监督——怎么办?这就是第 5 章的主题:gstack 方法论——虚拟工程团队。
留言板
欢迎在此分享你的想法!评论通过 GitHub Issues 存储,需要 GitHub 账号登录。