第3章: 规格驱动开发 —— 人类与AI的合约
"The specification is the source of truth, and code derives from it — not the other way around."
规格是真理的来源,代码派生自规格——而不是反过来。
——Deepak Babu Piskala, 《Spec-Driven Development: From Code to Contract in the Age of AI Coding Assistants》, 2026 年
第 2 章讲完了一个核心命题:Skill 是 AI Agent 的能力单元——一个 Markdown 文件定义一种行为,小而可组合,可复用可迭代。但这一章留下了一个尚未回答的问题:多个 Skill 组合在一起时,它们之间的"合约"是什么?谁来保证 /tdd 写的测试和 /grill-with-docs 对齐的需求是同一件事?
这就是规格驱动开发(Spec-Driven Development,SDD)要解决的问题。如果 Skill 是原子能力,那么 Spec 就是这些能力之间的接口协议。它不定义"怎么做",而是定义"做成什么样才算对"。
本章沿三条线索推进。第一条,SDD 的思想史——它的根源比 AI 编码工具早得多,但 AI 让它从学院派理想变成了工程必需品。第二条,三个代表性工具的逐层分析——OpenSpec、GitHub Spec-Kit、AWS Kiro。第三条,跨工具的通用原则。
三条线索汇聚到一句话:规格不是在浪费时间写文档——规格是你和 AI 之间最有效率的通信协议。
3.1 规格驱动从何而来
SDD 的思想根源比 AI 编码工具古老得多。它的前身可以追溯到四条工程实践线。
TDD(Kent Beck,1990 年代末)的核心洞见——测试本身就是一个可执行的规格。写完 expect(prefs.theme).toBe('system'),你实际上在声明:程序行为必须满足这个断言。契约式设计(Bertrand Meyer,1986)把模块之间的关系定义成契约——前置条件、后置条件、不变式。精确、可验证、不可含糊,这三个要素至今是 SDD 的质量标准。BDD(Dan North, 2003)把测试语言翻译成行为语言 Given-When-Then,开发者、测试者、业务分析师都能读同一份文档。形式化方法从 Hoare 逻辑到 TLA+,始终在回答一个问题:实现是否满足规格,能不能被证明?它没成为主流工程实践,但钉住了一个标准——好规格必须是可验证的。
这四条线各自独立跑了几十年,直到撞上一个共同的催化剂:AI 编码 Agent 能写代码了,但它不会读心。
2025 年是"Vibe Coding"元年——Karpathy 造出这个词之后,会写自然语言就能生出一个可运行的应用。但解放的另一面是失控。AI 写得极快,质量极不可靠——产物是"看起来能跑、生产环境里一碰就碎"的代码浆糊,不可测试、不可重构、不可理解。

2026 年风向变了。GitHub Spec Kit、OpenSpec、Kiro 三个工具同时爆发,GitHub Universe 和 AWS re:Invent 为 SDD 背书,半年内超过 20 个 AI 编码工具内置了规格驱动工作流。同年 1 月,arXiv 上的一篇论文给出了第一个系统化的 SDD 定义,并引用了受控实验数据:人工提炼过的规格可以让 LLM 生成代码的错误率降低高达 50%。
SDD 从四条各自独立的工程线索,被 AI 催化成了一个完整的范式。
3.2 OpenSpec:轻量级 SDD 的代表
OpenSpec 由 Fission-AI 团队开发,2025 年中首次发布,MIT 协议。GitHub 上 46,000+ Star,25 个以上的 AI 编码工具原生支持——从 Claude Code、Codex 到 Cursor、Windsurf、Copilot。
它的 GitHub 描述行很直接:"Spec-driven development for AI coding assistants."
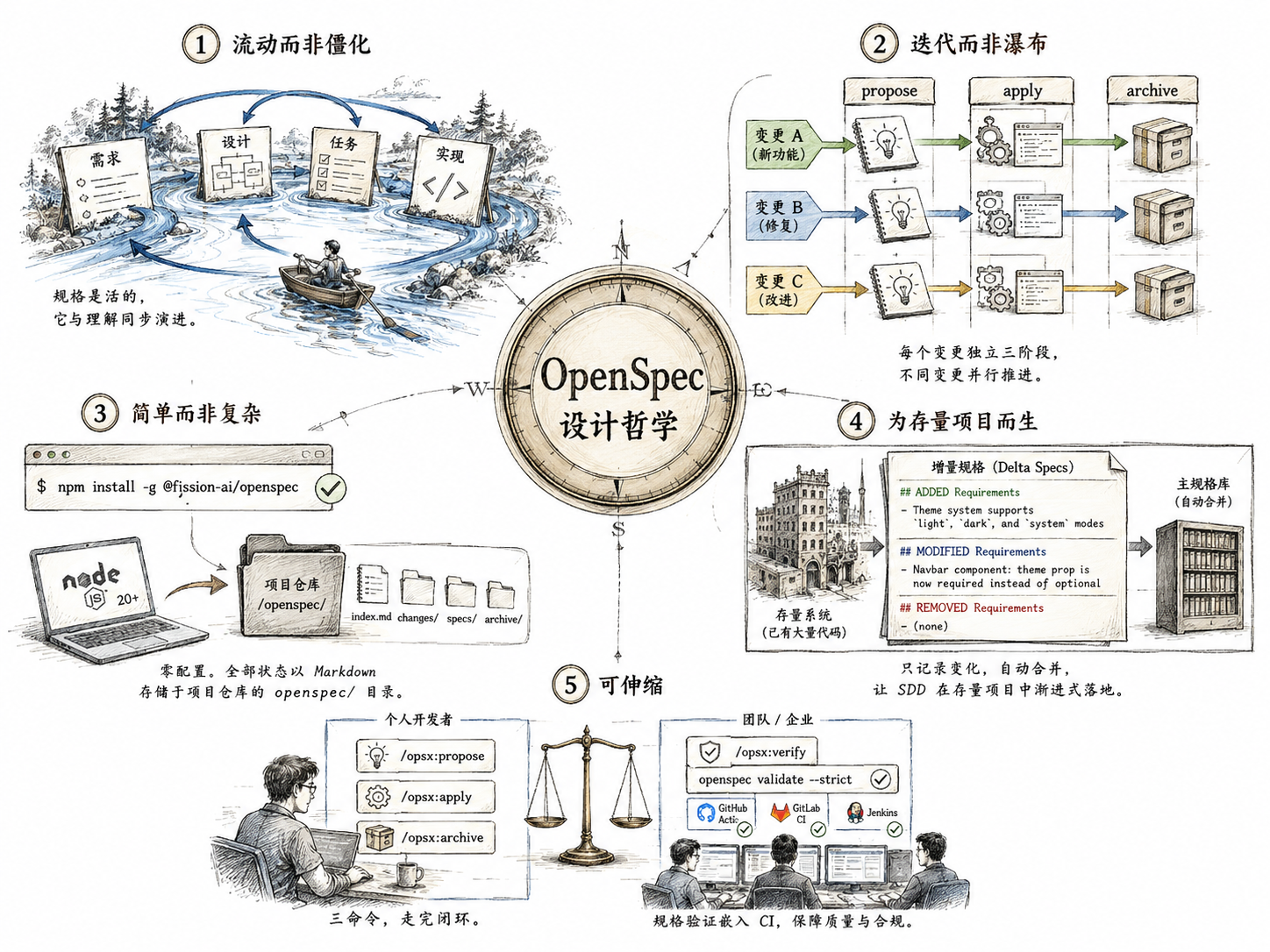
3.2.1 设计哲学:五句话
OpenSpec 的设计哲学可以归结为五句话:
1. Fluid, not rigid(流动而非僵化)。OpenSpec 不定义刚性阶段门。你不必严格按"需求→设计→任务→实现"的顺序线性推进。你可以在设计到一半时回到需求修改,可以在实现到一半时推翻设计。规格是活的——它和你对问题的理解同步演进。
2. Iterative, not waterfall(迭代而非瀑布)。OpenSpec 的工作单元是一个"变更"(Change)——对应于一个功能、一个修复、或一个改进。每个变更独立地走 propose → apply → archive 三阶段。没有全局阶段的约束——三个变更可以同时处于不同的阶段。
3. Easy, not complex(简单而非复杂)。安装只需要 Node.js 20+ 和一句 npm install -g @fission-ai/openspec(详见 3.2.2 节)。没有 Python 环境、没有数据库、没有配置文件。OpenSpec 的全部状态都以 Markdown 文件的形式存储在项目仓库的 openspec/ 目录下。
4. Built for brownfield, not just greenfield(为存量项目而生,不只为新项目)。这是 OpenSpec 最核心的差异点。大多数规格工具假设你从空项目开始——写一份规格,按规格实现。但现实中的多数项目是存量项目——已经有几万到几十万行代码,现在要往里加功能。你没法为了加一个暗黑模式就重写整个前端的规格。
OpenSpec 用 Delta Specs(增量规格) 应对这个场景。不需要重新描述整个系统的行为——只标记你改变了什么:
## ADDED Requirements
- Theme system supports `light`, `dark`, and `system` modes
## MODIFIED Requirements
- Navbar component: theme prop is now required instead of optional
## REMOVED Requirements
- (none)每个变更文件夹只包含相对于当前规格的变化。变更归档时,这些增量自动合并到主规格库中。这个设计让 SDD 可以在存量项目中渐进式地引入——今天为一个新功能写一份变更规格,明天为另一个功能再写一份。不需要一次性铺开。
5. Scalable(可伸缩)。从个人项目到企业级。单人开发者用三句核心命令(/opsx:propose、/opsx:apply、/opsx:archive)走完闭环。企业团队用 /opsx:verify 加 openspec validate --strict 将规格验证嵌入 CI。
3.2.2 安装与初始化
OpenSpec 是一套发布在 npm 上的 CLI 工具,包名为 @fission-ai/openspec,MIT 协议开源。GitHub 仓库 Fission-AI/OpenSpec,官方网站 openspec.dev。
前置要求:Node.js ≥ 20.19.0。 检查当前版本:
node --version安装 CLI:
# npm(推荐)
npm install -g @fission-ai/openspec@latest
# pnpm
pnpm add -g @fission-ai/openspec@latest
# yarn
yarn global add @fission-ai/openspec@latest
# bun(仍需 Node.js 20.19.0+ 在 PATH 中)
bun add -g @fission-ai/openspec@latest
# nix(直接运行,无需安装)
nix run github:Fission-AI/OpenSpec -- init验证安装成功:
openspec --version初始化项目:
进入项目目录,运行 openspec init:
cd your-project
openspec initopenspec init 会交互式引导你完成三件事:
- 选择 AI 编码工具——Claude Code、Cursor、Codex、Copilot、Windsurf、Gemini CLI、Cline、RooCode、Amazon Q 等 25+ 工具,OpenSpec 会为选定的工具自动配置对应的 slash 命令
- 选择 Profile——默认
core(包含 5 个核心命令);可切换为扩展 profile(包含 11 个命令) - 配置项目上下文——技术栈、编码规范、项目描述等
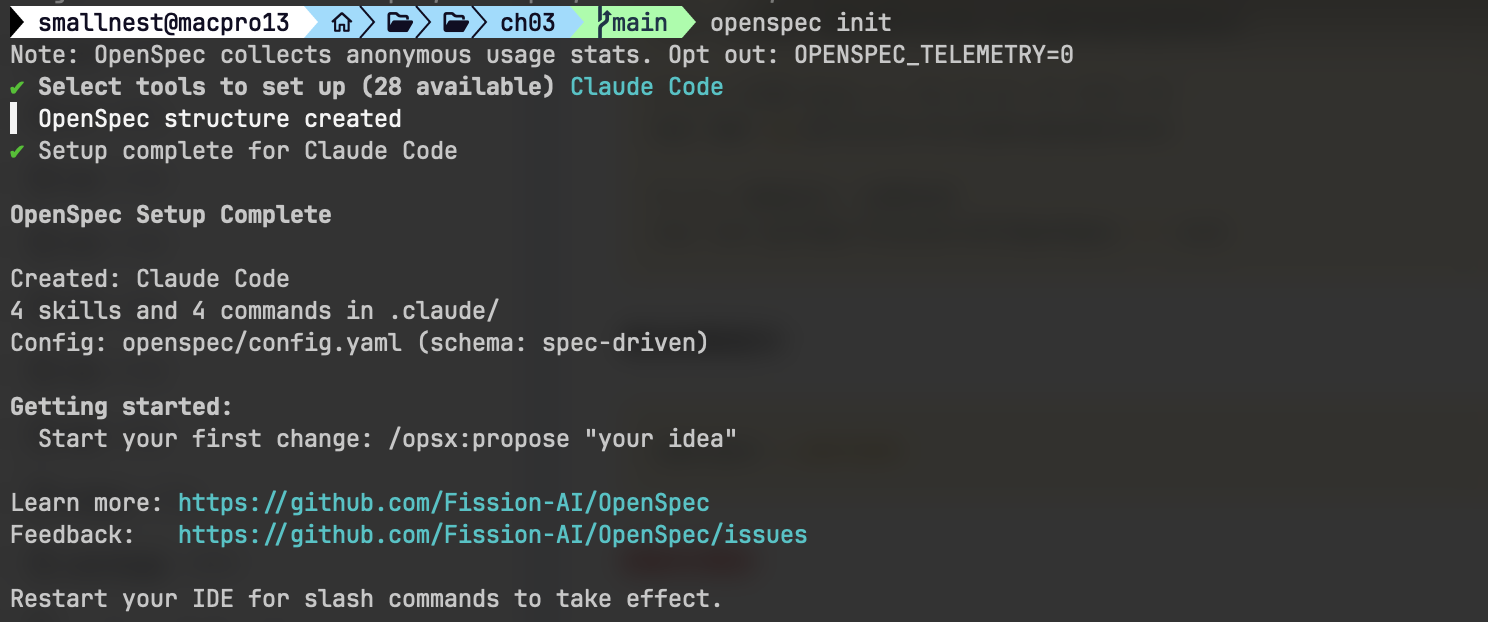
初始化完成后,项目根目录下生成 openspec/ 目录及对应工具的配置文件。
目录结构:
openspec/
├── specs/ ← 累积的项目规格知识库(系统真值)
│ └── <domain>/
│ └── spec.md
├── changes/ ← 活动变更(每个功能一个文件夹)
│ └── <change-name>/
│ ├── proposal.md
│ ├── design.md
│ ├── tasks.md
│ └── specs/ ← 增量规格(ADDED/MODIFIED/REMOVED)
│ └── <domain>/
│ └── spec.md
└── config.yaml ← 项目配置(可选)更新 CLI:
npm install -g @fission-ai/openspec@latest更新后,在每个项目中刷新 Agent 指令:
openspec update3.2.3 核心工作流:propose → apply → archive
OpenSpec 的三阶段工作流,简单到你不必绕过它:
/opsx:propose add-dark-mode
│
▼
┌─────────────────────────────────┐
│ openspec/ │
│ ├── changes/ │
│ │ └── add-dark-mode/ │
│ │ ├── proposal.md │ ← 为什么要做、影响什么
│ │ ├── specs/ │ ← 增量规格(ADDED/MODIFIED/REMOVED)
│ │ ├── design.md │ ← 技术方案(可选)
│ │ └── tasks.md │ ← 可逐个验证的任务清单
│ └── specs/ │ ← 累积的项目规格知识库
│ ├── theme-system.md │
│ └── navigation.md │
└─────────────────────────────────┘
│
▼
/opsx:apply → 逐任务实现,打勾 tasks.md
│
▼
/opsx:archive → 归档到 changes/archive/,增量合并到 specs//opsx:propose 是生成阶段。你告诉 AI 你要什么——可能是半句话的描述,也可能是一段详细的背景。AI 会向你提问来澄清歧义(类似 /grill-me 的机制,但没有那么穷举式),然后产出一个变更文件夹,包含:proposal.md(为什么做这个变更,影响哪些现有模块,有哪些风险)、specs/(增量规格,用 ADDED/MODIFIED/REMOVED 标记)、design.md(技术实现方案,可选)、tasks.md(分解为可逐个验证的任务列表)。
/opsx:apply 是执行阶段。AI 读取 tasks.md,逐个任务实现,完成一个打勾一个。关键是一次只做一个任务——这是 Pocock 在第 2 章中强调的"小而可组合"原则在规格层面的映射。如果一个任务在实现过程中发现需要偏离设计,AI 会停下来向你报告,而不是默默修改导致漂移。
/opsx:archive 是收尾阶段。变更完成并通过验证后,整个变更文件夹被移到 changes/archive/,增量规格自动合并到主规格库中。主规格库永远反映的是系统的当前状态——不是某个时间点的快照。下一次 /opsx:propose 会基于最新的主规格库来生成新变更的增量。
这个工作流的巧思在归档即合并。未归档的变更堆在 changes/ 下,每一项都在提醒"还有未完成的事"。归档不只是移动文件夹——它是变更从"临时提案"切换为"系统真值"。Meyer 的契约式设计在这里以最轻量的方式落地:每次归档,系统的契约被正式更新一次。
3.2.4 扩展工作流
三阶段之外,OpenSpec 提供了一系列可选命令,覆盖更复杂的场景:
| 命令 | 功能 | 使用场景 |
|---|---|---|
/opsx:new |
全流程初始化 | 项目首次接入 OpenSpec 时,建立目录结构和初始规格 |
/opsx:continue |
继续未完成的变更 | 上次 apply 到一半上下文窗口耗尽了,接着做 |
/opsx:ff |
快速跟进(Fast Forward) | 小变更不需要走完整流程,一次性生成全部产物 |
/opsx:verify |
验证一致性 | 检查实现是否与规格一致——对照 tasks.md 中打勾的项逐条验证 |
/opsx:sync |
规格同步 | 从现有代码反向提取规格,更新规格库(逆向 Spec-First) |
/opsx:bulk-archive |
批量归档 | 多个变更并行开发完成,一次性归档并检测冲突 |
/opsx:onboard |
新成员引导 | 生成项目的规格全景图,帮助新开发者(人或 AI)快速理解系统 |
值得特别指出的是 /opsx:sync。它是 OpenSpec 对"brownfield"承诺的技术兑现之一:可以先有代码,后有规格。对一个已有几万行代码的存量项目,运行 /opsx:sync 会让 AI 扫描代码库并反向生成初始规格库。这降低了 SDD 的入场成本——不需要为历史代码补写规格,AI 帮你做这件事。
/opsx:verify 和 openspec validate --all --strict --json(CLI 版本)是 CI 集成的关键。前者在 Agent 会话中交互式逐任务验证;后者产出结构化的 JSON 和退出码,可以被 GitHub Actions 或 Jenkins 直接消费——实现与规格不符,CI 红灯。
3.2.5 OpenSpec 的边界:它不做什么
理解一个工具,也要理解它选择不做什么。OpenSpec 有四个明确的边界:
不强制阶段门。 你不会被"必须先写 design.md 才能开始实现"拦住。OpenSpec 信任开发者的判断——如果你觉得这个变更简单到可以跳过设计,它不阻止你。代价是如果你跳过了然后在实现中走错了方向,你需要自己承担返工。
不做平台绑定。 OpenSpec 的规格是纯 Markdown 文件,不依赖任何特定 AI 工具的 API。同一个 openspec/ 目录可以无缝工作在 Claude Code、Codex、Cursor、Windsurf 之间。这是第 2 章中 Pocock 提出的"模型无关"原则在规格层面的表现。
不做自动代码生成。 OpenSpec 帮你定义"做什么"和"怎么做",但它不自己写代码。它把规格输出交给 AI 编码 Agent(通过 /opsx:apply)去执行。OpenSpec 的角色是"合约管理者",不是"代码生成器"。
不解决"人本身不会写规格"的问题。 这是所有 SDD 工具的终极瓶颈。工具可以提供模板、提出澄清问题、防止格式错误——但前提是使用它的人具备将模糊需求转化为可验证标准的能力。OpenSpec 不会救一个描述不清楚自己需求的人——它会放大你,正如第 1 章中反复出现的那个判断。
这四个边界定义出了 OpenSpec 的定位:它处于轻量自由的一端。GitHub Spec-Kit 则站在另一端。
3.2.6 实战:用 OpenSpec 生成贪吃蛇游戏
下面用一个完整的例子走一遍 OpenSpec 的三阶段闭环。任务:生成一个在浏览器中可玩的贪吃蛇网页游戏。
第一步:/opsx:propose snake-game
你只需要一句话:
/opsx:propose 做一个贪吃蛇网页游戏。用方向键控制蛇的移动,吃到食物
后蛇变长、分数增加。撞到墙壁或自己的身体则游戏结束。纯前端实现,
HTML/CSS/JS 单文件。Agent 不会直接开始写规格。它会先追问几个澄清问题:
Q1: 游戏网格大小你期望多少?我建议 20×20——适合桌面端,移动端也不会太小。
Q2: 蛇的移动速度?我推荐初始 150ms/步——有挑战但不至于太快。
Q3: 分数系统怎么设计?每个食物 10 分、显示当前分数和最高分?
Q4: 要不要加一个"重新开始"按钮?撞墙或咬到自己后弹出。
你逐一确认。Agent 随后在 openspec/changes/snake-game/ 下生成四个文件:
openspec/
├── changes/
│ └── snake-game/
│ ├── proposal.md ← 为什么做、影响范围、风险
│ ├── specs/
│ │ └── game-logic.md ← 增量规格(ADDED/MODIFIED/REMOVED)
│ ├── design.md ← 技术方案(可选)
│ └── tasks.md ← 可逐个验证的任务列表proposal.md 长这样:
# Proposal: 贪吃蛇网页游戏
## Why
提供一个可直接在浏览器中游玩的贪吃蛇游戏,作为项目的前端交互能力验证。
## What Changes
- 新增 `snake-game.html`,单文件包含 HTML/CSS/JS
- 不引入任何外部依赖
## Impact
- 纯新增文件,不影响现有模块
- 无后端依赖,无构建步骤specs/game-logic.md 中的增量规格只有 ADDED 部分:
## ADDED Requirements
### 游戏核心
- 20×20 网格,蛇初始长度 3,位于网格中央
- 方向键控制移动方向(上/下/左/右)
- 蛇不能反向移动(如向右时不能立刻向左)
### 食物系统
- 食物随机出现在空白格子,每次只有一个
- 蛇吃到食物后长度 +1,分数 +10
- 新食物立即在空白位置生成
### 游戏结束
- 蛇头触碰墙壁 → 游戏结束
- 蛇头触碰自身身体 → 游戏结束
- 游戏结束时显示最终得分和"重新开始"按钮
### 非功能需求
- 游戏循环间隔 150ms
- 最高分存储在 localStorage,刷新后保留
- 页面在 500ms 内完成首次渲染tasks.md 把实现拆成四个独立可验证的任务:
# Tasks
## 1. HTML 结构与画布渲染
- [ ] 创建 20×20 网格的 Canvas 元素
- [ ] 实现 `drawGrid()` 渲染网格线
- [ ] 实现 `drawSnake()` 渲染蛇身(绿色方块)
- [ ] 实现 `drawFood()` 渲染食物(红色方块)
- **验证**:打开页面看到空网格
## 2. 蛇的移动与键盘控制
- [ ] 实现方向状态管理(不允许反向)
- [ ] 实现 150ms 间隔的游戏循环
- [ ] 监听键盘方向键事件
- [ ] 实现蛇身移动逻辑(头前进、尾删除)
- **验证**:方向键控制蛇在网格中移动
## 3. 碰撞检测与食物逻辑
- [ ] 墙壁碰撞检测 → 游戏结束
- [ ] 自身碰撞检测 → 游戏结束
- [ ] 食物碰撞检测 → 蛇变长、分数+10、新食物生成
- [ ] 食物不生成在蛇身上
- **验证**:吃食物蛇变长,撞墙游戏结束
## 4. 分数系统与游戏状态
- [ ] 当前分数和最高分显示
- [ ] localStorage 读写最高分
- [ ] 游戏结束弹窗(显示分数 + 重新开始按钮)
- [ ] 重新开始重置所有状态
- **验证**:完整一局从开始到结束到重新开始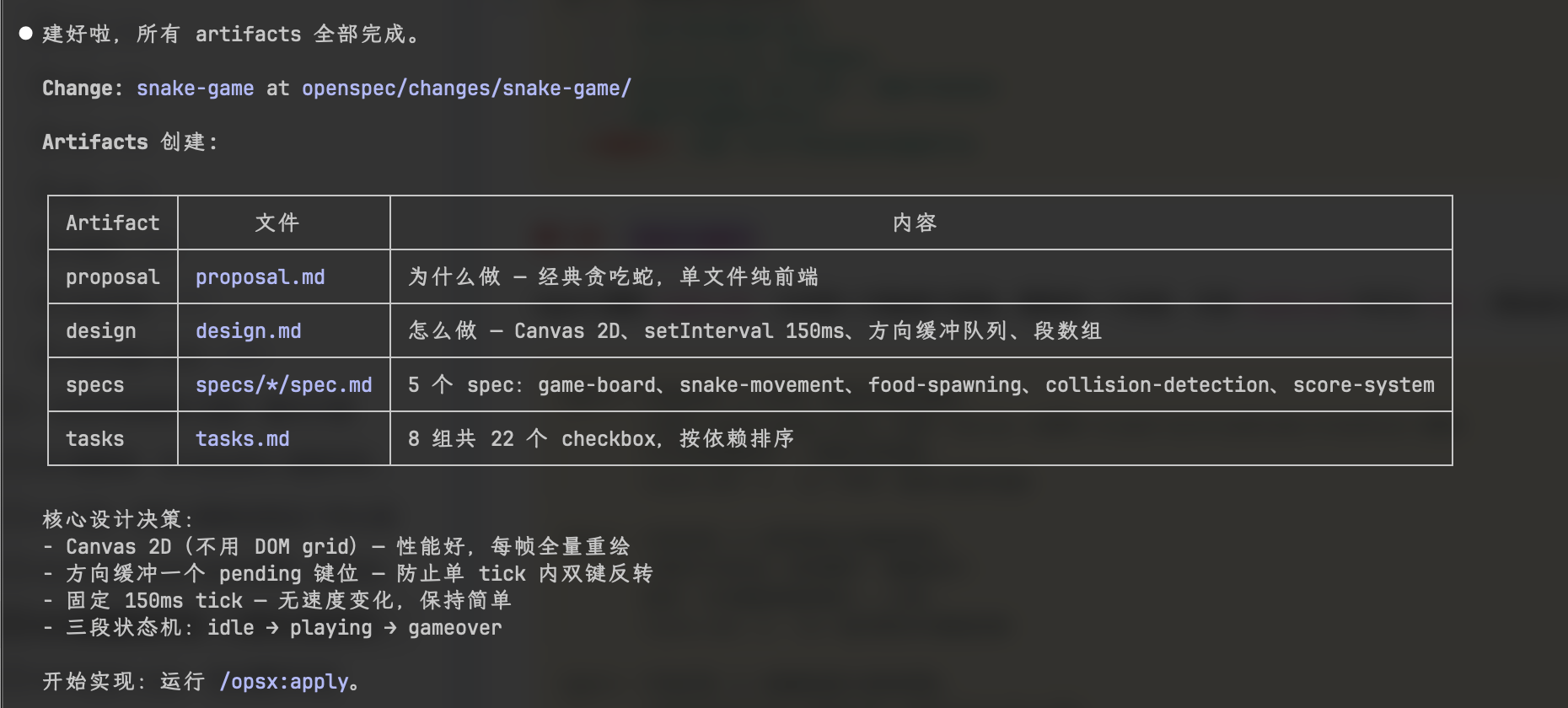
第二步:/opsx:apply
Agent 读取 tasks.md,从任务 1 开始逐个实现。每完成一个任务,它在 tasks.md 中打勾 [x],然后进入下一个:
Agent: 开始任务 1——HTML 结构与画布渲染。
[生成 snake-game.html,包含 Canvas 元素和 drawGrid/drawSnake/drawFood 函数]
打开浏览器预览 → 网格正常渲染。
tasks.md: 1. [x] HTML 结构与画布渲染
Agent: 开始任务 2——蛇的移动与键盘控制。
[添加方向状态、游戏循环、键盘监听]
测试:方向键控制蛇移动 → 正常。
tasks.md: 2. [x] 蛇的移动与键盘控制
Agent: 开始任务 3——碰撞检测与食物逻辑。
[在游戏循环中加入碰撞检测,实现食物生成与消费]
测试:吃食物蛇变长,撞墙结束 → 正常。
tasks.md: 3. [x] 碰撞检测与食物逻辑
Agent: 开始任务 4——分数系统与游戏状态。
[添加分数面板、localStorage 读写、结束弹窗、重新开始按钮]
测试:完整一局正常 → 正常。最高分刷新后保留 → 正常。
tasks.md: 4. [x] 分数系统与游戏状态四个任务全部打勾,apply 阶段结束。
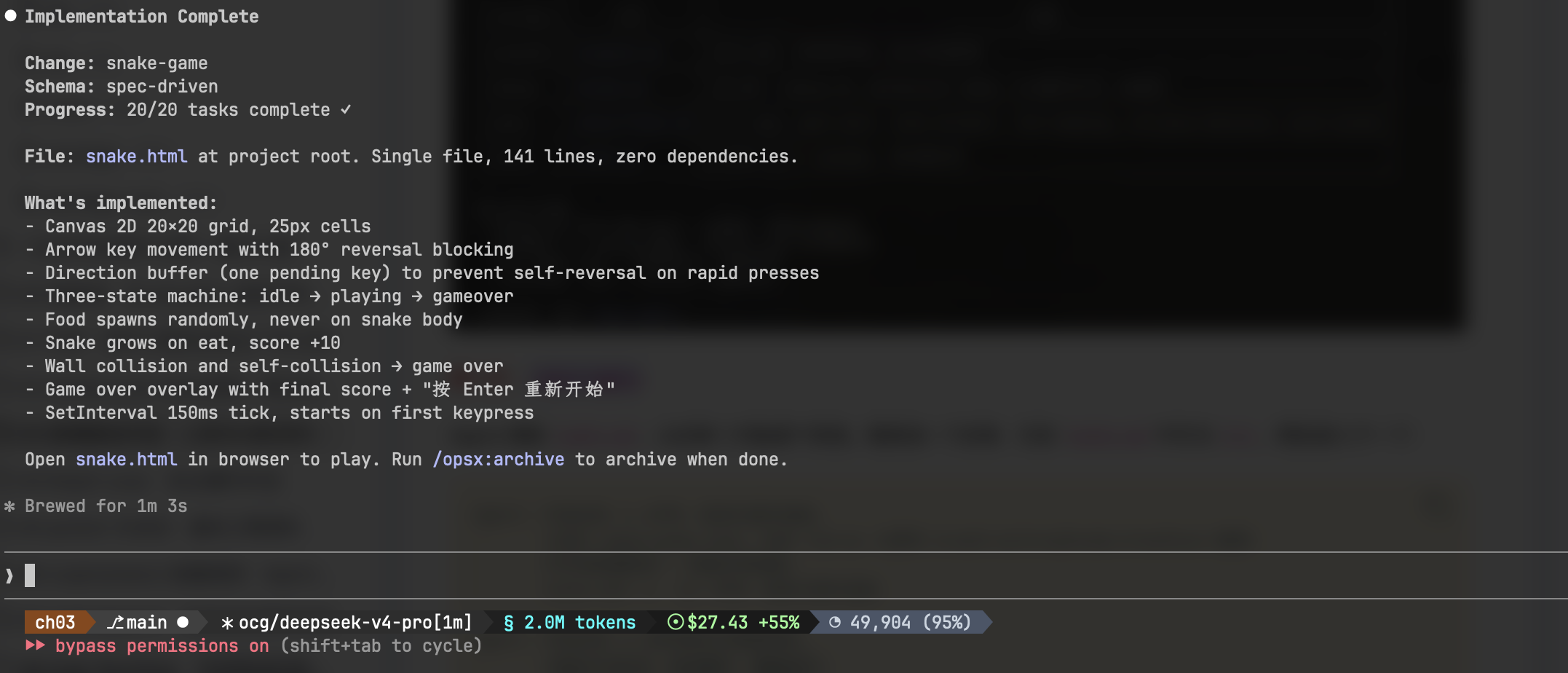
第三步:/opsx:archive
/opsx:archive snake-gameAgent 执行三个动作:将 changes/snake-game/ 整体移到 changes/archive/snake-game/;将 specs/game-logic.md 中的 ADDED 增量合并到主规格库 openspec/specs/game-logic.md;输出归档摘要:"snake-game 已归档。主规格库中的 game-logic.md 已更新,新增 12 条行为规格。"
自此,贪吃蛇游戏的完整规格永久留在了项目的 openspec/specs/ 目录中。六个月后如果有人要重构它——比如把 Canvas 换成 DOM 渲染——规格告诉 TA 游戏应该怎么工作,不管实现层怎么变。
这就是 OpenSpec 的增量变更机制的意义。重构时不需要重新定义"游戏行为"——只需要声明"渲染层实现方式变了,行为不变"。流程如下:
第一步:/opsx:propose snake-dom-render
描述变更内容,明确声明这是一个修改而非新增:
/opsx:propose 将贪吃蛇游戏的渲染层从 Canvas 换为 DOM div 网格。
游戏行为不变——所有游戏逻辑、碰撞检测、分数系统的行为
保持与现有规格一致。仅替换渲染实现。Agent 检测到主规格库 openspec/specs/ 中已存在 game-logic.md,自动识别被影响的 capability,生成变更文件夹:
openspec/changes/snake-dom-render/
├── proposal.md ← "Why: 提高语义化、可访问性"
├── specs/
│ └── game-logic.md ← 增量规格(只写变更部分)
├── design.md ← "DOM 网格方案替代 Canvas API"
└── tasks.md ← 四个迁移任务specs/game-logic.md 的增量规格自动标注为 MODIFIED,只写变更部分,保留所有原有行为申明:
## MODIFIED Requirements
### 渲染层
- ~~使用 Canvas API 的 drawGrid/drawSnake/drawFood 函数~~
- 使用 DOM div 元素渲染 20×20 网格,每个格子一个 `<div>` 节点
- 蛇身格子使用 `.snake` CSS class,食物格子使用 `.food` CSS class
- 渲染性能:单帧重绘 < 50ms,保持 150ms 游戏循环不受影响
## RETAINED Requirements
以下行为申明保持不变(来自主规格库 game-logic.md):
- 20×20 网格,蛇初始长度 3,位于网格中央
- 方向键控制移动方向(上/下/左/右)
- 蛇不能反向移动
- 食物随机出现在空白格子,每次只有一个
- 蛇吃到食物后长度 +1,分数 +10
- 撞墙或自碰 → 游戏结束
- 最高分存储在 localStorage
- 游戏循环间隔 150ms
- 首次渲染 < 500ms第二步:/opsx:apply
Agent 逐任务执行。关键约束:每完成一个任务,Agent 对照 MODIFIED + RETAINED 双清单验证——新实现同时满足变更要求和保留行为:
Agent: 开始任务 1——DOM 网格结构。
将 Canvas 替换为 20×20 div 网格,每格添加 .cell class。
✓ 网格渲染正常,原有行为未受影响
Agent: 开始任务 2——DOM 渲染函数。
实现 renderGridDom()/renderSnakeDom()/renderFoodDom()。
✓ 蛇移动正常,食物生成正常,原有行为未受影响
Agent: 开始任务 3——替换渲染调用。
gameLoop 中 Canvas 调用全部替换为 DOM 调用。
✓ 碰撞检测正常,分数系统正常,原有行为未受影响
Agent: 开始任务 4——无障碍与样式。
添加 aria-label、键盘焦点、网格线样式。
✓ 原有路径测试全部通过,game-logic.md 中的 RETAINED 行为均验证通过第三步:/opsx:archive snake-dom-render
归档时,OpenSpec 将 MODIFIED 部分合并到主规格库 openspec/specs/game-logic.md——渲染层描述从 Canvas 更新为 DOM,RETAINED 行为不变。规格仍然是系统的准确真值。
这就是归档即合并的威力:每次归档,规格被正式更新一次,而非重新写一次。 重构不是一次重新写规格的过程,而是一次更新规格中一个子集的过程。规格保留了所有未变行为的完整性——六个月前的游戏行为申明,六次重构后仍然可信。
整个流程用了三个命令、四个任务、一次归档。OpenSpec 的轻体现在这里:它没有要求你写 constitution、没有强制阶段门、没有生成八份文档。它只做了一件事——在你写代码之前冻结了一份关于"完成意味着什么"的共识。
3.3 GitHub Spec-Kit:重量级 SDD 的基建
2025 年 9 月,GitHub 发布了名为 Spec-Kit 的开源工具包。它的定位简洁而明确——GitHub 官方博客的原话是:"Specifications don't serve code — code serves specifications."(规格不服务于代码——代码服务于规格。)
这句话翻转了传统的层级:规格才是源,代码是派生品。
Spec-Kit 在不到一年内积累了超过 92,000 个 GitHub Stars,30+ 个 AI 编码工具支持,近 100 个社区扩展。2026 年 5 月,微软在 Build 大会上为它安排了专门的培训模块和主题演讲。Thoughtworks 在 2026 年 4 月的技术雷达中将 Spec-Kit 列入"评估"环——他们的评价精准地总结了它的核心特征:"一种更重量级的方案,拥有刚性阶段门、大量的 Markdown 文档、Python 运行环境。"
3.3.1 设计哲学:以 constitution.md 为纲
Spec-Kit 用六条原则定义了它的世界观:
规格是主,代码是仆。 这个表述比 OpenSpec 的"规格先行"更强硬。它隐含的推论是:如果代码和规格不一致,永远是代码错了。
先定宪法,再写代码。 一个名为 constitution.md 的文件是 Spec-Kit 最独特的设计。这个文件不是功能需求——它是项目的不变法则:编码规范、TDD 要求、安全标准、部署约束、不合规的代价。在后续每个阶段中,Agent 都必须检查"我的产出是否符合宪法?"这就像一个国家在制定法律之前先有宪法的约束——一切下位法不能违宪。
刚性阶段门。 Spec-Kit 定义了五个强制阶段外加三个可选阶段。理论上你可以跳过某个阶段,但框架的设计强烈鼓励按序执行:Constitution → Specify → Plan → Tasks → Implement。每个阶段有明确的输入和输出。
可扩展。 社区贡献了近 100 个扩展——Jira 集成、Azure 部署、成本追踪、无障碍检查、安全审计、多 Agent 审查。Spec-Kit 本身是一个骨架,扩展是肌肉。
多 Agent 支持。 30+ 个 AI 编码工具原生支持——从 GitHub Copilot 到 Claude Code 到 Amazon Q Developer。Spec-Kit 用同一个 /speckit.* 命令体系跨平台运作。
全生命周期覆盖。 从初始化到退役,Spec-Kit 试图覆盖一个功能在代码库中的完整生命周期——不只是"写代码",还有"理解已有代码"、"变更影响分析"、"退役清理"。
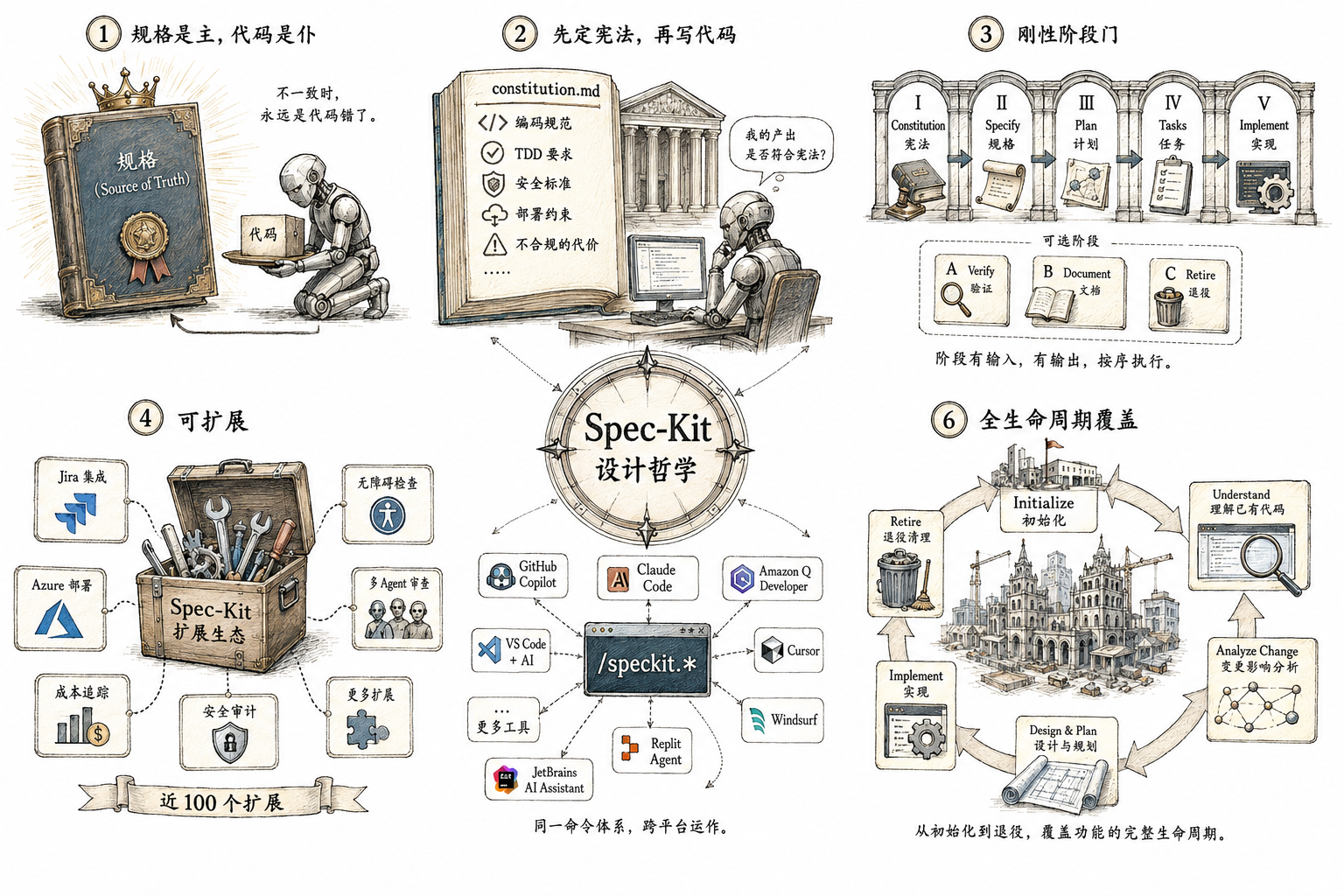
3.3.2 核心流程:五步法+三个可选步骤
/speckit.constitution → 定义项目的不变法则
│
▼
/speckit.specify → 编写功能规格(用户故事、验收标准、非功能需求)
│
▼
/speckit.plan → 生成技术方案(架构、数据流、组件树、API 契约)
│
▼
/speckit.tasks → 将方案分解为可独立验证的任务清单
│
▼
/speckit.implement → 逐任务实现五个步骤之间是三个可选命令:/speckit.clarify(在 specify 和 plan 之间插入一轮需求澄清——类似于 /grill-with-docs 的领域建模过程)、/speckit.analyze(在 plan 之前分析变更的影响范围——哪些现有模块会被触及,风险在哪里)、/speckit.checklist(在 implement 完成后生成一个验证清单——对照原规格逐条确认)。
constitution.md 的设计值得深入讨论,因为它是 Spec-Kit 与 OpenSpec 之间最深层的哲学分歧。
# constitution.md
## 编码标准
- 语言:TypeScript,严格模式
- 格式:Prettier 默认配置
- 禁止使用 `any` 类型(除非有明确的 ADR 记录偏差理由)
## 测试要求
- 每个功能必须有单元测试,覆盖率不低于 80%
- 每个 API 端点必须有集成测试
- 不满足测试要求不得进入 implement 阶段
## 安全要求
- 所有用户输入必须经过验证
- 所有外部 API 调用必须有超时和重试策略
- 敏感信息(密钥、密码、PII)禁止出现在日志中
## 架构约束
- 遵循 Clean Architecture 的分层模型
- 新增依赖必须过审——优先使用现有依赖
- API 契约变更必须更新对应的 OpenAPI 文档和版本号
## 违规后果
- CI 红灯,阻止 merge
- 违规需要在 ADR 中记录决策理由和批准的例外情况宪法不告诉你"做什么功能"。它告诉你"在这个仓库里,怎么写代码才算合格"。因为它是宪法——不可变或只能通过正式的修正案来修改——Agent 在每一步都知道它的行为边界在哪里。
Pocock 在第 2 章中的批评"GSD、BMAD、Spec-Kit 这类方法通过接管流程来帮助你,但同时夺走了你的控制权",指的主要是这种刚性。在 OpenSpec 中,proposal.md 简单到你手动改一行就能用。在 Spec-Kit 中,流程是一个系统,离开流程的代价是失去了框架提供的验证和宪法检查。
两种选择的优劣没有绝对答案。如果团队在高度监管的行业开发(医疗、金融、政府),如果需要为审计留下完整的决策记录,如果面临多个团队并行开发同一代码库的协调复杂度——Spec-Kit 的刚性的价值远超其成本。如果是一个人在做 startup 的 MVP,每天需要快速迭代验证方向——OpenSpec 的轻量自由更合适。用第 1 章的话说:工具的选择取决于你的"信号需求"——你需要多强的信号来确定代码在做你期望它做的事。
3.3.3 Spec-Kit 中文增强版:spec-kit-zh
Spec-Kit 生态中还有一个给中国开发者的项目:spec-kit-zh。不是简单的汉化——它针对中文开发环境做了几项实际适配:
- 完整的汉化输出:AI 生成的规格、任务、审查报告全部以中文输出。不是机翻,而是用中文技术写作的惯用表达重构了模板
- 国内工具链适配:预设了 Gitee、极狐 GitLab、阿里云效 Codeup 的项目模板
- 10+ 主流 AI 编码工具支持:除了 Claude Code、Codex、Copilot 之外,还包括通义灵码、文心快码等国内 AI 编码工具
- 中文开发场景适配:在 constitution 模板中预设了符合国内团队习惯的编码规范、commit 规范、CR 流程
这代表了 SDD 生态向中国市场的延伸——它标志着 SDD 不再是一个英语社区的孤立运动,而是正在形成全球化的工具生态。
3.3.4 实战:用 Spec-Kit 生成贪吃蛇游戏
同一个贪吃蛇任务,用 Spec-Kit 走一遍。体会一下流程感的差异。
第零步:/speckit.constitution
Spec-Kit 要求先定宪法。启动命令后,Agent 引导你逐条确定项目的不变法则:
/speckit.constitutionAgent: 我先建议一份宪法草案,你可以逐条确认或修改。
生成的 constitution.md:
# constitution.md
## 编码标准
- 语言:HTML/CSS/JavaScript(纯前端,无框架)
- 格式:2 空格缩进,单引号,分号结尾
- 禁止使用 var,使用 const/let
## 测试要求
- 每个游戏逻辑函数必须有对应的单元测试
- 使用 Jest 或 Vitest 作为测试运行器
- 关键用户路径(开始→移动→吃食物→死亡→重新开始)必须有集成测试
## 安全要求
- 不使用 eval() 或 innerHTML 注入
- localStorage 读写必须有 try-catch 包裹
## 架构约束
- 游戏逻辑与渲染逻辑分离
- 状态管理集中在一个 gameState 对象中
- 新增 npm 依赖需要过审
## 违规后果
- 代码审查时逐条对照宪法检查
- 违规禁止合入第一步:/speckit.specify
/speckit.specify 做一个贪吃蛇网页游戏。方向键控制,吃食物变长得分,
撞墙或撞到自己结束。纯前端单文件。Agent 基于宪法和需求生成 spec.md:
# Spec: 贪吃蛇网页游戏
## 用户故事
### US-1: 作为玩家,我可以用方向键控制蛇的移动
验收标准:
1. 按下 ↑ 键,蛇向上移动一格
2. 按下 ↓ 键,蛇向下移动一格
3. 按下 ← 键,蛇向左移动一格
4. 按下 → 键,蛇向右移动一格
5. 蛇不能反向移动(如当前向右时,← 键无效)
### US-2: 作为玩家,吃到食物后蛇变长、分数增加
验收标准:
1. 蛇头碰到食物格子时,食物消失,蛇长度 +1
2. 分数显示 +10
3. 新食物立即在空白位置随机生成
4. 新食物不与蛇身位置重叠
### US-3: 作为玩家,撞墙或撞到自己时游戏结束
验收标准:
1. 蛇头坐标超出 20×20 网格边界 → 游戏结束
2. 蛇头坐标与蛇身任一格子重叠 → 游戏结束
3. 游戏结束时显示最终得分
4. 显示"重新开始"按钮,点击后重置游戏
### US-4: 作为玩家,最高分在刷新后保留
验收标准:
1. 游戏结束时如果当前分数 > 历史最高分,更新最高分
2. 最高分存储在 localStorage 中
3. 刷新页面后最高分仍然显示
4. localStorage 不可用时游戏正常运行(仅当前分数可用)
## 非功能需求
- NFR-1: 游戏循环间隔 150ms
- NFR-2: 首次渲染时间 < 500ms
- NFR-3: 不依赖任何外部库或框架第二步:/speckit.clarify(可选)
执行 /speckit.clarify,Agent 会再扫一轮规格中的模糊点:
Agent: 有一个歧义需要澄清——蛇的初始方向是什么?我建议初始方向为"静止",玩家按下第一个方向键后蛇才开始移动。这样可以避免玩家还没准备好蛇就撞墙了。
用户同意。这条澄清被追加到 US-1 的第 6 条验收标准中。
第三步:/speckit.plan
Agent 读取 spec.md 和 constitution.md,生成 plan.md:
# Plan: 贪吃蛇网页游戏
## 架构概览
```
index.html
├── <canvas id="game"> ← 游戏画布(400×400px)
├── <div id="score-board"> ← 分数面板
└── <div id="game-over-modal"> ← 结束弹窗
snake-game.js
├── gameState ← 集中状态管理
│ ├── snake: [{x, y}] ← 蛇身坐标数组
│ ├── food: {x, y} ← 食物坐标
│ ├── direction: 'UP'|'DOWN'|'LEFT'|'RIGHT'
│ ├── score: number
│ └── isGameOver: boolean
├── gameLoop() ← 150ms 间隔主循环
├── moveSnake() ← 蛇身移动逻辑
├── checkCollision() ← 碰撞检测(墙壁 + 自身)
├── checkFoodCollision() ← 食物碰撞检测
├── spawnFood() ← 食物随机生成
├── saveHighScore() / loadHighScore() ← localStorage 读写
└── resetGame() ← 重置状态
game.test.js ← 单元测试
```
## 数据流
键盘事件 → 更新 gameState.direction
→ gameLoop 每 150ms 触发
→ moveSnake() 计算新蛇头位置
→ checkCollision() 检测墙壁/自身 → 可能设置 isGameOver
→ checkFoodCollision() 检测食物 → 可能更新 score、spawnFood()
→ drawGrid() / drawSnake() / drawFood() 重绘画布
→ 更新 score-board DOM第四步:/speckit.tasks
/speckit.tasksAgent 将 plan 分解为依赖排序的任务,每个任务标注对应的验收标准:
# Tasks
## Task 1: 项目骨架与画布渲染 (依赖: 无)
- 创建 index.html 和 snake-game.js
- 初始化 400×400 Canvas
- 实现 drawGrid / drawSnake / drawFood
- 覆盖: US-1 的前置条件(网格可见)
- 验证: 打开页面看到空白网格
## Task 2: 游戏状态管理与蛇的移动 (依赖: Task 1)
- 实现 gameState 对象
- 实现 moveSnake() 和方向校验(禁止反向)
- 实现 150ms gameLoop
- 绑定键盘事件
- 覆盖: US-1 AC 1-5
- 验证: 方向键控制蛇移动,不能反向
## Task 3: 碰撞检测与食物系统 (依赖: Task 2)
- 实现 checkCollision(墙壁 + 自身)
- 实现 checkFoodCollision(蛇头 vs 食物)
- 实现 spawnFood(随机、不与蛇重叠)
- 覆盖: US-2 AC 1-4, US-3 AC 1-2
- 验证: 吃食物→变长得分,撞墙→游戏结束
## Task 4: UI 与分数系统 (依赖: Task 3)
- 实现分数面板 DOM 更新
- 实现游戏结束弹窗 + 重新开始按钮
- 实现 resetGame()
- 覆盖: US-3 AC 3-4, US-4 AC 1-4
- 验证: 完整游戏流程 + 最高分持久化
## Task 5: 测试 (依赖: Task 4)
- 编写 game.test.js
- 游戏逻辑函数的单元测试
- 完整用户路径的集成测试
- 覆盖: 所有 US 的所有 AC
- 验证: npm test 全部通过注意 Spec-Kit 和 OpenSpec 的一个关键差异:Spec-Kit 的 Task 5 是独立的测试任务——它把测试从实现中分离出来,要求你在实现完成后专门写一轮测试。而 OpenSpec 的 TDD 式工作流中,测试和实现在同一个垂直切片里交替进行。这是两种哲学的直接体现:Spec-Kit 更接近传统的"实现→验证"线性模型,OpenSpec 更接近 Pocock 的"RED→GREEN→REFACTOR"循环。
第五步:/speckit.implement
Agent 从 Task 1 开始顺序执行。和 OpenSpec 的不同之处在于——每一步实现后,Agent 除了打勾任务之外,还会对照 constitution.md 检查合规性:
Agent: 开始 Task 1——项目骨架与画布渲染。
[创建文件,实现 Canvas 和渲染函数]
✓ Task 1 完成
✓ 宪法检查通过:无外部依赖、无 eval、使用 const/let
Agent: 开始 Task 2——游戏状态管理与蛇的移动。
[实现 gameState、moveSnake、gameLoop、键盘监听]
✓ Task 2 完成
✓ 宪法检查通过:状态集中在 gameState 对象中
⚠ 宪法提醒:gameLoop 和 moveSnake 可测试性不足——将在 Task 5 中补测试
Agent: 开始 Task 3——碰撞检测与食物系统。
[...]
Agent: 开始 Task 4——UI 与分数系统。
[...]
Agent: 开始 Task 5——测试。
[生成 game.test.js,运行 npm test]
✓ 12 个单元测试通过
✓ 2 个集成测试通过
✓ 宪法检查通过:测试覆盖率 94%,超过 80% 门槛第六步:/speckit.checklist(可选收尾)
/speckit.checklistAgent 生成最终验证清单,逐条对照原规格:
✓ US-1: 方向键控制 (AC 1-6 全部满足)
✓ US-2: 食物与分数 (AC 1-4 全部满足)
✓ US-3: 游戏结束 (AC 1-4 全部满足)
✓ US-4: 最高分持久化 (AC 1-4 全部满足)
✓ NFR-1: 游戏循环 150ms — 实测 148-152ms
✓ NFR-2: 首次渲染 320ms < 500ms
✓ NFR-3: 零外部依赖Spec-Kit 用了六个命令、五个任务、外加宪法检查和 checklist 收尾。流程比 OpenSpec 长,但每一步产出的文档和验证记录更完整。如果你在合规性要求的行业,这些记录就是审计轨迹——谁来审都能追溯"这个功能为什么长这样、谁在什么时间验证了它"。
3.4 AWS Kiro:SDD 内置的 IDE
如果 OpenSpec 和 Spec-Kit 是"在现有 AI 编码工具上加上规格工作流",AWS Kiro 则更进一步——它是一个从头开始以 SDD 为设计中心的完整 IDE。
Kiro 于 2025 年中期发布,架设在 Amazon Bedrock 之上(Claude 推理,Amazon Nova 高吞吐量代码生成),是 AWS 在 AI 编码工具领域的旗舰产品。它的定位很清晰:规格是工作单元(Unit of Work)。 不是聊天记录,不是 prompt,不是随手写的便签——是有结构、有版本、可审计的规格文件夹。
3.4.1 三种工作流:覆盖开发的全场景
Kiro 在 2026 年初将它的规格体系扩展为三种互补的工作流,每一种对应一种真实的开发场景:
标准工作流(Standard):最经典的 SDD 模式——用户描述需求,Kiro 生成三份文档。requirements.md 使用 EARS 格式(Easy Approach to Requirements Syntax)编写,一种受 IEEE 标准启发但大幅简化的需求语法。它强制每个需求写清楚触发条件("当用户点击保存按钮时")、系统响应("系统应将偏好写入 localStorage")、异常处理("如果 localStorage 不可用,系统应回退到默认值并输出 console.warn")。design.md 是技术设计——组件层次、数据流、序列图、API 契约、数据库 schema。tasks.md 是依赖排序的任务列表,每个任务绑定对应的测试。
设计先行工作流(Design-First):为"我已经想好技术方案了,帮我把它形式化"的场景而设计。开发者从一个已有的架构想法开始——可能是手绘的组件图、伪代码、甚至是一段被否掉的原型代码——Kiro 反向推导出 requirements.md 和 design.md,再正向生成 tasks.md。这个工作流降低了 SDD 的入场门槛——不需要从空白需求开始,可以从已有的设计出发。AWS 的 Stephanie Walter 评价说:"这是 Kiro 承认了现实——开发者的行为习惯胜过方法论的说教。先构思再形式化,这种混合策略让 SDD 更容易被团队接受。"
Bugfix 工作流:这是三种工作流中最特别的一个,因为它代表了一种"外科手术式"的精确变更模式。在一个有几十万行代码的存量项目中,为了修一个 bug 写一份完整的功能规格是多余的开销。Bugfix 工作流只要求三样东西:当前行为(Current Behavior)——WHEN-THEN 格式,精确描述 bug 的表现。"WHEN 用户在 Firefox 隐私窗口中打开设置页 THEN 页面白屏,console 报 QuotaExceededError";期望行为(Expected Behavior)——修复后应该发生什么。"WHEN 用户在 Firefox 隐私窗口中打开设置页 THEN 页面正常渲染,主题回退到跟随系统,console 输出警告而非报错";不变行为(Unchanged Behavior)——明确声明"修复这个 bug 时绝对不能破坏什么"——这是最容易被忽略却最重要的一条。"应用主题切换功能的所有其他行为应保持不变。localStorage 可用时的偏好保存逻辑不应被修改。相关的单元测试应继续通过。"
Kiro 基于这三份描述生成两类测试:确认 bug 存在的测试(验证修复前行为)和属性测试(Property-Based Tests)——验证修复后不变行为未被破坏。这种设计将一次性的调试行为转化为持久化的测试资产,与第 2 章中 /diagnose 的 Phase 5(回归测试)一脉相承。
3.4.2 Steering Files:Agent 的持久记忆
Kiro 的另一个原创概念是 Steering Files(引导文件)——放在 .kiro/steering/ 目录下的持久化 Markdown 文件,编码了跨会话的约束和知识。它的逻辑与第 2 章中 Pocock 的 CONTEXT.md 高度同构,但结构性更强:
.kiro/
├── steering/
│ ├── coding-standards.md ← 编码规范(类似 ESLint 配置的精神,但用自然语言)
│ ├── architecture.md ← 架构约束(不可触及的模块边界)
│ ├── security.md ← 安全要求(认证模型、数据加密、敏感信息处理)
│ ├── dependencies.md ← 依赖策略(新增库必须过审、版本锁定规则)
│ └── testing.md ← 测试标准(覆盖率门槛、测试类型要求)
└── specs/
└── add-dark-mode/
├── requirements.md
├── design.md
└── tasks.mdSteering Files 和规格(specs)之间的关系很像第 2 章中的"全局 Skill"和"任务级指令"之间的关系。Steering Files 是"凡是这个项目的东西都要遵守"的跨功能约束,规格是"这个功能要实现的"功能级行为。两者都存放在 .kiro/ 目录中,一起构成了项目的 AI 开发环境。
3.4.3 Kiro 的位置:重量级 SDD 的企业端
Kiro 带来的不只是功能,更是一种工作方式的选择。它的存在主义问题是:为了获得治理能力、审计能力、安全控制,你愿意放弃多少灵活性?
答案取决于场景。Dion Hinchcliffe(The Futurum Group)对此的判断是:"企业要回答的问题不是'这个工具慢不慢',而是'它能不能在可测量的程度上降低变更失败率和平均恢复时间'。"
Kiro 的定价也体现了它的定位:从免费层(50 credits/月)到 Power 层($200/月,10,000 credits)。多模型支持意味着不同复杂度的任务可以使用不同成本的模型——简单的格式化用 Qwen (0.05x),复杂的架构设计用 Claude (1x)。这和 Kiro 的"按场景选择工具"哲学一以贯之。
但 Kiro 有几个局限不全是 bug,一定程度上是 SDD 作为方法论的固有张力:
- SDD 引入额外开销。 为一句话的改动("把按钮颜色换成蓝色")走完
requirements → design → tasks → implement全流程是荒谬的。Kiro 官方的回应是"不是所有任务都需要 SDD"——但这个判断需要使用者自己下,Kiro 并没有自动推荐合适的工作流。 - EARS 格式可能产生"假精度"。 格式良好的需求不等于内容正确的需求。一个需求可以完美地遵循 EARS 语法,同时描述的行为完全是错的。形式不保证实质。
- 规格漂移仍然存在。 Kiro 的规格是在开发前生成的,实施完成后不会自动更新。除非配置 Agent Hooks 来检测漂移,否则规格和实现之间的鸿沟会默默扩大。
Kiro 在 2026 年代表的是"企业重量级"这一端——与 OpenSpec 的自由轻量、Spec-Kit 的治理完备构成一个从轻到重的连续选择区间。
3.4.4 实战:用 Kiro 生成贪吃蛇游戏
还是同一个贪吃蛇任务。在 Kiro 中,你不需要先安装任何 CLI 或配置目录结构——打开 IDE,创建一个空白项目,直接在 Kiro 的规格面板中开始。
选择工作流:Standard
Kiro 启动后弹出工作流选择:Standard / Design-First / Bugfix。选 Standard——我们从一个自然语言需求开始。
第一步:编写需求,Kiro 生成 EARS 格式规格
在 Kiro 的规格编辑器中输入:
做一个贪吃蛇网页游戏。方向键控制蛇移动,吃食物后蛇变长、分数增加。
撞墙或撞到自己则游戏结束。纯前端单文件实现,最高分用 localStorage 保存。Kiro 读取这段描述,生成 requirements.md——使用 EARS 格式:
# Requirements: 贪吃蛇网页游戏
## R1: 游戏初始化
WHEN 玩家打开页面时,
THE SYSTEM SHALL 渲染一个 20×20 的游戏网格,
AND 在网格中央放置一条长度为 3 的蛇,
AND 在随机空白位置生成一个食物,
AND 显示当前分数(初始为 0)和历史最高分。
## R2: 蛇的移动
WHEN 玩家按下方向键(↑ ↓ ← →)时,
THE SYSTEM SHALL 更新蛇的移动方向为对应方向,
UNLESS 新方向与当前方向相反(如当前向右时按 ←),
IN WHICH CASE THE SYSTEM SHALL 忽略该按键输入。
WHEN 游戏循环计时器(间隔 150ms)触发时,
THE SYSTEM SHALL 将蛇头向当前方向移动一格,
AND 从蛇尾移除一格。
## R3: 食物消费
WHEN 蛇头坐标与食物坐标重叠时,
THE SYSTEM SHALL 移除该食物,
AND 将蛇长度增加 1 格,
AND 将当前分数增加 10 分,
AND 在随机空白位置生成一个新食物。
IF 没有空白格子可用(极罕见,蛇填满整个网格),
THEN THE SYSTEM SHALL 判定玩家胜利,显示"你赢了!"并停止游戏循环。
## R4: 碰撞与游戏结束
WHEN 蛇头坐标超出 20×20 网格边界时,
THE SYSTEM SHALL 判定游戏结束。
WHEN 蛇头坐标与蛇身任一格子重叠时,
THE SYSTEM SHALL 判定游戏结束。
WHEN 游戏结束时,
THE SYSTEM SHALL 停止游戏循环,
AND 比较当前分数与 localStorage 中的最高分(若当前分更高则更新),
AND 显示游戏结束弹窗(包含最终得分和"重新开始"按钮)。
## R5: 重新开始
WHEN 玩家点击"重新开始"按钮时,
THE SYSTEM SHALL 重置蛇位置、蛇长度、移动方向、当前分数和食物位置,
AND 重新启动游戏循环,
AND 不重置 localStorage 中的最高分。
## R6: 降级处理
IF localStorage 不可用(隐私模式、存储已满),
THEN THE SYSTEM SHALL 回退到内存存储(最高分仅在当前会话中保留),
AND 在浏览器 console 中输出警告信息。
## 非功能需求
- NFR1: 游戏循环间隔 150ms(±10ms 容差)
- NFR2: 页面首次渲染在 500ms 内完成
- NFR3: 无外部库或框架依赖
- NFR4: 键盘输入响应延迟 < 50msEARS 的特征在这里变得很明显:每条需求都以 WHEN/IF/THEN/SHALL/UNLESS 之一开头,触发条件和系统响应被强制分离。这种结构让自然语言需求变得可自动化验证——你可以写一个脚本逐条扫描需求文档,检查每条是否包含 WHEN 和 THEN 子句。
第二步:Kiro 生成 design.md
你确认需求后,Kiro 基于 requirements.md 和 .kiro/steering/ 目录中的 Steering Files 生成 design.md。如果你还没有 Steering Files,Kiro 会提示你:"检测到 .kiro/steering/ 为空。建议在实现前先配置 coding-standards.md 和 testing.md,或跳过此步直接使用默认设置。"
(这里我们假设已经配置了基础的编码规范。)
design.md 的核心内容:
# Design: 贪吃蛇网页游戏
## 组件树
```
index.html
└── <body>
├── <div class="game-container">
│ ├── <div class="score-board"> ← 当前分数 / 最高分
│ └── <canvas id="game-canvas"> ← 游戏画布 400×400
└── <div class="modal" id="game-over-modal"> ← 游戏结束弹窗
├── <p class="final-score">
└── <button id="restart-btn">
snake-game.js
├── // === 状态层 ===
│ const state = {
│ snake: Array<{x: number, y: number}>,
│ food: {x: number, y: number},
│ direction: 'UP' | 'DOWN' | 'LEFT' | 'RIGHT',
│ nextDirection: 'UP' | 'DOWN' | 'LEFT' | 'RIGHT',
│ score: number,
│ highScore: number,
│ gameOver: boolean,
│ gameLoopId: number | null,
│ }
│
├── // === 逻辑层 ===
│ initGame(), moveSnake(), checkCollision(),
│ checkFoodCollision(), spawnFood(),
│ endGame(), resetGame()
│
├── // === 渲染层 ===
│ drawGrid(), drawSnake(), drawFood(),
│ updateScoreBoard(), showGameOverModal()
│
├── // === 持久化层 ===
│ loadHighScore(), saveHighScore()
│
└── // === 主循环 ===
gameLoop() → 每 150ms 调用一次
snake-game.test.js ← 单元测试 + 集成测试
```
## 序列图(游戏主循环的单次迭代)
```
gameLoop() →
moveSnake() →
计算新蛇头位置 →
检查反向约束 →
更新 state.snake
checkCollision() →
墙壁碰撞?→ endGame()
自身碰撞?→ endGame()
checkFoodCollision() →
吃到食物?→ score += 10, spawnFood()
drawGrid() → drawSnake() → drawFood()
updateScoreBoard()
```
## 关键决策
- 使用 `nextDirection` 缓冲解决快速连续按键的方向丢失问题
- 键盘事件写入 `nextDirection`,gameLoop 读取后同步到 `direction`
- 防止两帧之间多次按键导致蛇反向移动
- Canvas API 而非 DOM 渲染:20×20 网格、400px 画布的渲染规模下 Canvas 性能更优第三步:Kiro 生成 tasks.md
# Tasks: 贪吃蛇网页游戏
## T1: 项目结构与渲染层 [预估: 20min]
依赖: 无
- 创建 index.html 和 snake-game.js
- 初始化 Canvas 并实现 drawGrid / drawSnake / drawFood
关联测试: testDrawGrid, testDrawSnake
关联需求: R1
## T2: 状态管理与蛇的移动 [预估: 30min]
依赖: T1
- 实现 state 对象
- 实现 moveSnake() 和反向约束
- 实现 gameLoop()(150ms 间隔)
- 绑定键盘事件 → nextDirection
关联测试: testMoveSnake, testDirectionReverseBlocked, testKeyboardBinding
关联需求: R2
## T3: 碰撞检测与食物系统 [预估: 25min]
依赖: T2
- 实现 checkCollision()(墙壁 + 自身)
- 实现 checkFoodCollision()、spawnFood()
关联测试: testWallCollision, testSelfCollision, testFoodCollision, testSpawnFoodNotOnSnake
关联需求: R3, R4
## T4: 游戏结束与分数系统 [预估: 20min]
依赖: T3
- 实现 endGame()、showGameOverModal()
- 实现 loadHighScore()、saveHighScore()(含 localStorage 降级)
- 实现 updateScoreBoard()
关联测试: testHighScorePersistence, testLocalStorageFallback
关联需求: R4, R5, R6
## T5: 重新开始与集成测试 [预估: 15min]
依赖: T4
- 实现 resetGame()
- 编写完整流程集成测试:开始→移动→吃食物→死亡→重新开始
关联测试: testFullGameFlow
关联需求: R5注意 Kiro 在 tasks.md 中多了一个字段:关联测试和关联需求。每个任务都明确标注了它覆盖哪些需求、对应哪些测试。这不是装饰——Kiro 的 Agent Hooks 会在实现完成后自动做追溯验证:运行关联测试,检查通过状态,确认每条需求的关联测试全部通过后才标记"完成"。这是 Kiro 在 SDD 三个工具中独有的能力——需求到测试的追溯矩阵是自动维护的,不需要手动管理。
第四步:实现(Kiro 内置 Agent 执行)
点击 "Implement All" 或逐个任务执行。Kiro 的 Agent 按 T1→T5 顺序执行,每个任务完成后自动运行关联测试。Steering Files 在整个过程中持续生效——Agent 在每次生成代码前都会检查 .kiro/steering/ 中的约束:
[T1] 实现中... → 检查 coding-standards.md → const/let, 单引号, 分号 ✓
[T1] 运行关联测试 → testDrawGrid ✓, testDrawSnake ✓
[T1] 完成 ✓
[T2] 实现中... → 检查 coding-standards.md ✓
[T2] 运行关联测试 → testMoveSnake ✓, testDirectionReverseBlocked ✓, testKeyboardBinding ✓
[T2] 完成 ✓
...
[T5] 实现中...
[T5] 运行关联测试 → testFullGameFlow ✓
[T5] 运行全部测试套件 → 18/18 通过 ✓
[T5] 完成 ✓第五步:验证
Kiro 自动弹出验证报告,追溯矩阵一目了然:
需求追溯报告 — 贪吃蛇网页游戏
R1 (游戏初始化) → testDrawGrid ✓, testDrawSnake ✓ → 覆盖 ✓
R2 (蛇的移动) → testMoveSnake ✓, testDirectionReverseBlocked ✓, testKeyboardBinding ✓ → 覆盖 ✓
R3 (食物消费) → testFoodCollision ✓, testSpawnFoodNotOnSnake ✓ → 覆盖 ✓
R4 (碰撞与结束) → testWallCollision ✓, testSelfCollision ✓ → 覆盖 ✓
R5 (重新开始) → testFullGameFlow ✓ → 覆盖 ✓
R6 (降级处理) → testLocalStorageFallback ✓ → 覆盖 ✓
NFR1 (150ms循环) → 实测 146-153ms ✓
NFR2 (首次渲染) → 实测 280ms ✓
NFR3 (零依赖) → 确认 ✓
NFR4 (输入延迟) → 实测 8-14ms ✓
全部 6 条需求覆盖通过,全部 4 条 NFR 满足。Kiro 在 2026 年的独特价值正是这个自动追溯。OpenSpec 和 Spec-Kit 都有验证机制,但两者都需要你手动运行验证命令或对照 checklist 检查。Kiro 因为规格、设计、任务、测试、Steering Files 都在同一个 IDE 环境内,能做到保存时自动验证——你改了一行代码,IDE 立刻告诉你"这个改动让 R3 的测试失败了"。这是 IDE 原生 SDD 独有的体验,也是 Kiro 和两个 CLI 工具之间最根本的差异。
三个工具,同一个贪吃蛇任务,三种不同的体验。OpenSpec 用三个命令一个归档走完全程——快,轻,存量为先。Spec-Kit 用六步流程加上宪法和 checklist——重,但每一步都有完整的文档和治理记录。Kiro 把规格、设计、任务、测试、约束整合到一个 IDE 面板中——贵,但追溯矩阵和自动验证不需要你手动维护。
选哪个?如果你在给一个现存项目加功能,OpenSpec 的增量规格不会让你写无用的文档。如果你在新项目启动阶段、需要为六个月的多人协作建立治理框架,Spec-Kit 的宪法体系能省掉大量后续的争论。如果你的团队已经在 AWS 生态中、需要为审计和合规留存完整的追溯记录,Kiro 是当前最完善的盒装方案。工具的三岔路口没有正确选项——只有和你的现状最匹配的选项。
3.5 SDD 的关键原则
三个工具的细节讨论完了。现在提炼跨工具的通用原则。不管你选 OpenSpec、Spec-Kit、Kiro,还是自己写 Makefile 手工管理规格,这些原则都成立。
3.5.1 规格先行,代码在后
这是 SDD 最核心的原则,也是它和 Vibe Coding 最根本的区别。
"先写规格再写代码"的本质是什么?不是多了一步流程。是冻结了承诺与验证之间的间隙。 在 Vibe Coding 中,承诺和验证发生在同一个时刻——对 AI 说"给我做一个登录页",看一眼产出的代码,"看起来不错",结束。事前没有定义"不错"的标准,事后没有对照标准来验证。用视觉直觉代替了工程判断。
在 SDD 中,承诺时间和验证时间被有意识地分离了。你先定义"登录页完成了"意味着什么——至少三条用户故事、六条验收标准、两条非功能需求——然后 AI 才被允许开始写代码。写完之后,你不是"看一眼",而是逐条对照规格中的验收标准来判定是否通过。
这个分离就是契约的本质。契约的价值不在措辞精确——在它独立于履约方存在。你可以用它评判任何代码:今天 AI 写的、明天人写的、后天另一个 AI 重构的。规格是判据,代码是答卷。
3.5.2 规格是活文档
SDD 中最难的不是"写一份好规格"——是"六个月后代码改了一百次,规格仍然是对的"。
这就是"活文档"原则的含义:规格不是写完就归档的一次性产出,而是随代码同步演进的系统真值。 它的反面是"僵尸规格"——曾经对过、现在已不反映现实、但还安静地躺在仓库里,没人敢删,也没人敢信。
僵尸规格比没有规格更危险。后者至少让人知道"我不确定这个东西的行为是什么",前者让人相信一个假的描述。AI Agent 尤其容易掉进这个陷阱——它不会怀疑一份 Markdown 文件的时效性。
活文档需要工具支撑。OpenSpec 用 archive 自动合并增量到主规格库;Spec-Kit 用 checklist 在实现后逐条验证;Kiro 用 Agent Hooks 在每次保存时检查漂移。工具各有不同,但原则相同:每次代码变更都必须触发一次规格的"是否仍然正确"的检查。
3.5.3 规格粒度适中
太粗的规格无法指导实现。"用户应该能管理自己的偏好"——太模糊了,AI 可以理解成任何东西:偏好 API?偏好 UI?偏好持久化层?歧义空间太大。
太细的规格退化为瀑布式文档。"偏好页面的保存按钮应位于页面右下角,与取消按钮间距 16px,使用 primary 色号 #1890ff"——这种级别的细节应该在设计和实现阶段自然涌现,不应该在需求规格中预设。过早过细的规格消灭了实现过程中的合理探索空间。
"适中"的粒度是什么?一个实用的标尺:一个变更一个文件夹,包含 proposal + specs + design + tasks。 Proposal 说清"为什么"和"什么范围";Specs 说清功能需求和非功能需求;Design 说清"技术怎么做";Tasks 说清"先做哪个后做哪个"。四个文件之间信息不重复,每个只承担一个维度的描述责任。
这个结构和第 2 章中 Pocock 的"一个 Skill 只做一件事"在本质上是同一个原则:关注点分离。 不要把所有信息塞进一份文档——分开写,让每个文档精确、短小、可独立更新。
3.5.4 规格必须可验证
一个验收标准写成"主题切换应该流畅"是无效的。"流畅"是一个主观形容词——你、我、AI 对"流畅"的定义各不相同。你对 AI 说"这个切换不够流畅",AI 不知道你的意思是慢了 100ms、卡了一帧、还是动画曲线不对。
正确的写法是:"当用户切换主题时,页面应在 100ms 内应用新的主题样式,视觉上没有可见的闪烁或样式跳跃。"这个描述可测量、可自动化测试、可被 Agent 验证。AI 知道"做完"的标准。
SDD 的精髓在这里:规格的质量由可验证性决定,不由可读性决定。 一个自检问题:你能写一个自动化测试来验证这条规格吗?如果不能,这条规格就不完整。
几个提升可验证性的技巧:
- 每条验收标准关联至少一个测试用例
- 用数字代替副词——"应快速加载"变成"应在 200ms 内完成加载"
- 穷举边界条件——"当输入为空时"、"当输入超过长度限制时"、"当网络不可用时"
- 用"如果 X,那么 Y"代替"应该支持 X"——明确触发条件和预期结果
3.5.5 规格应与平台和模型解耦
这是第 2 章中 Pocock 的"模型无关"原则在规格层面的自然延伸。好的规格用 Markdown 写,存放在 Git 仓库中,可以被任何 AI 编码工具读取。它不绑定 Claude Code 的 /opsx 前缀,不绑定 Kiro 的 .kiro/ 目录结构,不绑定任何模型的特定 API。
这个原则在 2026 年特别重要,因为工具生态在快速变化。今天用 Claude Code + OpenSpec,明天团队可能换到 Copilot + Spec-Kit。如果规格是平台绑定的,迁移成本会阻止你作出正确的工具决策。如果规格是纯 Markdown,迁移只意味着改变目录结构和命令前缀——核心的规格资产不受影响。
3.6 三个工具的对比
OpenSpec、Spec-Kit、Kiro 是 SDD 的三种选择,不是三个竞争品。它们的差异本质上是对几个核心权衡的不同立场。
| 维度 | OpenSpec | Spec-Kit | Kiro |
|---|---|---|---|
| 理念 | 流动的增量 | 刚性宪法 + 全生命周期 | SDD 内置 IDE,规格即工作单元 |
| 强制力 | 引导(建议走提案→归档) | 刚性阶段门(框架强烈建议按序执行) | 内置工作流(三种模式可选切换) |
| 安装复杂度 | 低(npm install) | 中(Python 3.11 + uv + GitHub Token) | 中(IDE 安装,需 AWS 账号) |
| 核心创新 | Delta Specs(增量规格),brownfield 优先 | constitution.md(项目宪法) | Steering Files + EARS 需求语法 |
| 规格管理 | 增量合并 + 版本归档 | 宪法约束 + 全文档生成 | 工作流模式驱动 + Hooks 自动检测 |
| 模型/平台依赖 | 无 | 无(但 Python 运行时) | AWS Bedrock(但支持多模型) |
| AI 工具支持 | 25+ | 30+ | Kiro IDE/CLI(不支持外部 Agent 平台) |
| 中文适配 | 社区 fork(openspec-cn) | 官方中文版(spec-kit-zh) | 支持中文输出 |
| CI/CD | 强(openspec validate --json) |
中(有限的 CLI 支持) | 中(通过 Agent Hooks) |
| 最佳场景 | 存量项目、快速迭代、个人/小团队 | 新项目、合规性行业、大团队 | 重度 AWS 环境、企业治理、安全审计 |
这个对比表的用意不是"选一个最好的"——根据自己的真实需求找到适合自己的工具。许多团队在实践中走混合路径:用 Kiro 做需求分析和架构设计,用 OpenSpec 管理增量变更,用 Spec-Kit 的宪法思想为仓库添加一个 CONTRACT.md 文件。工具可以组合,原则不变。
3.7 本章小结
规格驱动开发不是 AI 时代的发明。它的思想根源可以追溯到 1843 年 Ada Lovelace 的第一个程序规格,经过 TDD、契约式设计、BDD、形式化方法四条线索的独立演进,在 2025-2026 年被 AI 编码工具的爆发催化成一个完整的工程范式。
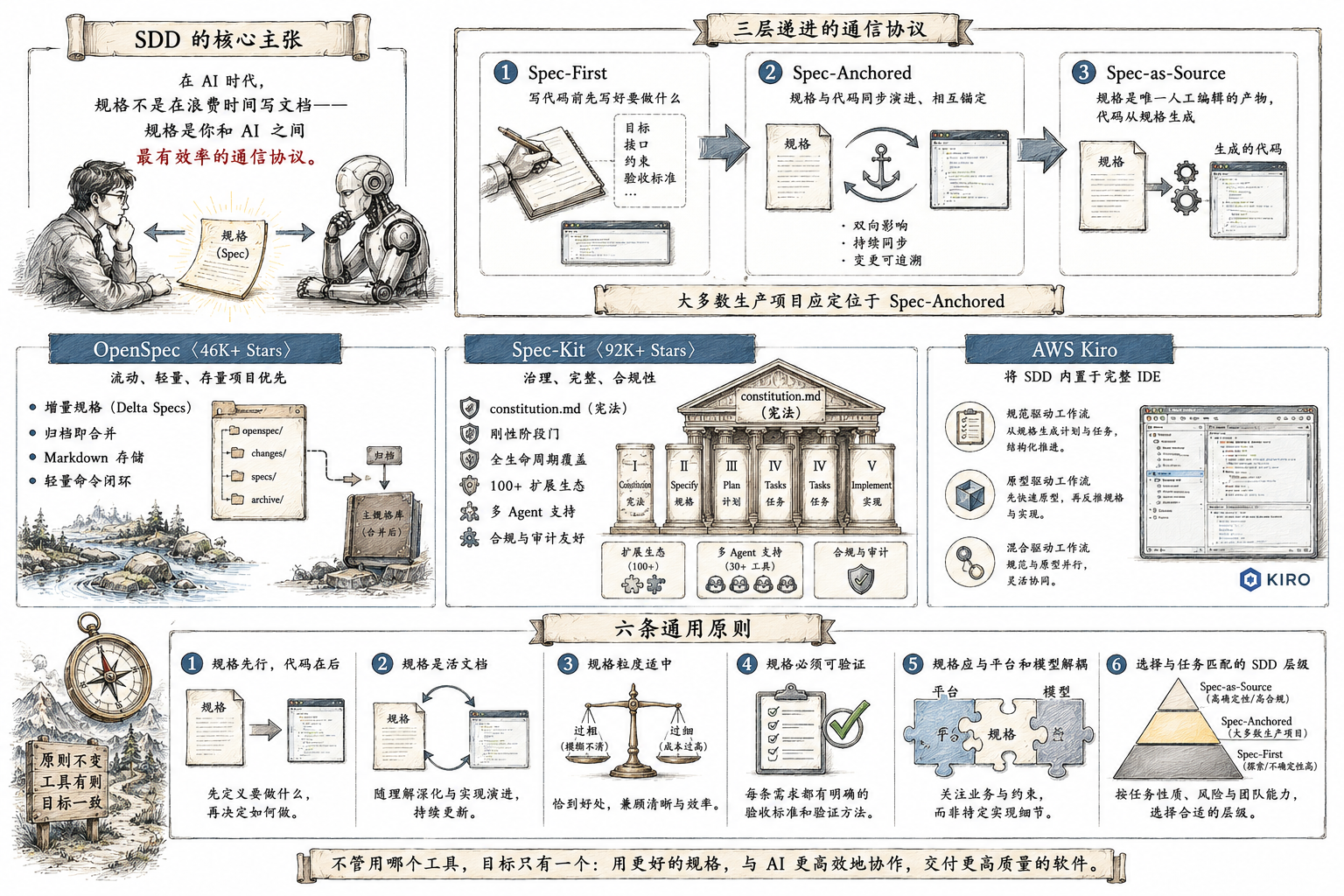
SDD 的核心主张凝聚在一句话里:在 AI 时代,规格不是在浪费时间写文档——规格是你和 AI 之间最有效率的通信协议。
这个通信协议有三层递进:Spec-First(写代码前先写好要做什么)、Spec-Anchored(规格与代码同步演进相互锚定)、Spec-as-Source(规格是唯一人工编辑的产物,代码从规格生成)。大多数生产项目应定位于 Spec-Anchored。
OpenSpec(46K+ Stars)追求流动、轻量、存量项目优先——用增量规格和"归档即合并"降低 SDD 的入场成本。Spec-Kit(92K+ Stars)追求治理、完整、合规性——用宪法文件和刚性阶段门保证全生命周期的规格一致性。AWS Kiro 则将 SDD 内置于完整 IDE 中,提供了三种互补的工作流。
不管用哪个工具,六条原则通用:规格先行,代码在后;规格是活文档;规格粒度适中;规格必须可验证;规格应与平台和模型解耦;选择与任务匹配的 SDD 层级。
第 2 章回答了"一个可复用的 AI 工程能力单元应该如何设计"。本章回答了"当多个能力单元组合在一起时,它们之间的合约应该长什么样"。Skill 和 Spec 的关系是:Skill 定义怎么做(能力单元),Spec 定义做成什么样(合约)。 前者是工具,后者是判据。两者合一,才构成完整的 AI 工程化体系。
Spec 定义了一次需要做什么。当需求在多个迭代中持续演化、当需要 AI 在循环中逐步改进自己的产出时,Spec 本身还不够——还需要一个自我循环改进的机制:AI 实现了、验证了、发现不对劲、重新修改、再次验证、直到满足 Spec。这就是下一章的主题:Ralph Loop——自主循环开发。
留言板
欢迎在此分享你的想法!评论通过 GitHub Issues 存储,需要 GitHub 账号登录。